Structural Equation Modeling: Foundations and Applications
Introduction
Structural Equation Modeling (SEM) is a comprehensive statistical methodology that combines factor analysis and multiple regression techniques to examine complex relationships among observed and latent variables. Over the past few decades, SEM has become a powerful tool for researchers across disciplines such as social sciences, psychology, education, business, and health sciences. This chapter introduces the theoretical underpinnings of SEM, its key components, and practical applications, with an emphasis on latent variables and path analysis.
Key Concepts in SEM
1. Observed and Latent Variables
Observed Variables: These are directly measured variables, often referred to as indicators. For example, responses to survey items like “I enjoy learning” and “I find studying rewarding” can serve as observed variables for the latent construct “Motivation.”
Latent Variables: These are unobserved constructs that are inferred from observed variables. SEM excels in estimating latent variables while accounting for measurement error.
2. Measurement Error
Measurement error is the discrepancy between the observed value and the true value of a variable. SEM explicitly incorporates measurement error into its models, which sets it apart from traditional regression approaches.
3. Path Diagrams
Path diagrams visually represent SEM models. Key components include:
Circles: Represent latent variables.
Squares: Represent observed variables.
Arrows: Depict causal relationships or associations.
구조방정식 모형(SEM)의 주요 장점
1. 관찰변수 + 잠재변수를 동시에 모델링할 수 있다
SEM의 가장 큰 장점은 Measurement model(측정모형) 과 Structural model(구조모형) 을 한 번에 추정한다는 점. 즉, 측정 오류를 통제하면서 이론적 관계(경로)를 분석할 수 있다.
반면 PROCESS(Hayes)는 관찰변수 기반 회귀분석 → 측정오류를 반영하지 못함.
2. 복잡한 이론 모델을 깔끔하게 설계할 수 있다
다중 매개(multiple mediation)
연속 매개(sequential / serial mediation)
다중 조절(multiple moderation)
조절된 매개(mod moderated mediation)
매개된 조절(mediated moderation)
다집단 분석(multi-group analysis)
잠재성장모형(LGM)
확인적 요인분석(CFA)
3. 전체 모형 적합도를 평가할 수 있다 (Fit indices)
회귀나 PROCESS는 “이 관계가 유의한가?” 까지만. SEM은 더 나아가 “이 모델 전체가 데이터에 얼마나 잘 맞는가?” 를 평가할 수 있음
4. 오차 간 상관(Residual covariance)이나 제약을 자유롭게 줄 수 있음
그렇다면 왜 SEM이 ’계수가 잘 흔들린다’고 느껴질까?
SEM은 모델을 어떻게 그리느냐에 따라 추정값이 달라지는 구조이기 때문.
오차 간 상관을 허용하면 계수가 바뀜
불필요한 경로를 제거하면 전체 계수가 변화
측정모형의 factor loading 구조에 따라 구조경로가 변함
Components of SEM
1. Measurement Model
The measurement model specifies the relationships between latent variables and their observed indicators. It answers the question: How well do the observed variables measure the underlying construct?
Example: Motivation as a latent variable might be measured by three observed items:
\[
Motivation \sim Item_1 + Item_2 + Item_3
\]
2. Structural Model
The structural model specifies the relationships between latent variables (or between latent and observed variables). It answers the question: What are the causal relationships between constructs?
Example: Testing whether motivation mediates the relationship between hours studied and test performance:
\[
Test\_Score = Motivation + Hours\_Studied
\]
\[
Motivation = Hours\_Studied
\]
Steps in Conducting SEM
Step 1: Define the Model
Develop a theoretical model based on prior research or hypotheses. Clearly specify the relationships among variables in a path diagram. (탐색적 분석에는 부적합)
Step 2: Specify the Model
Translate the path diagram into a set of equations. This involves defining the measurement and structural models.
Step 3: Collect Data
Ensure the dataset includes sufficient sample size and all observed indicators for latent variables.
Step 4: Estimate the Model
Use software such as R (lavaan package), AMOS, Mplus, or LISREL to estimate the parameters.
Step 5: Evaluate Model Fit
Examine fit indices and modify the model, if necessary, based on theoretical justifications.
Step 6: Interpret the Results
Interpret path coefficients, factor loadings, and fit indices in the context of your research question.
Cronbach’s Alpha: A Measure of Reliability
Introduction
Cronbach’s Alpha (α) is a widely used statistic in research to assess the internal consistency reliability of a set of items or indicators. It is particularly useful for measuring the reliability of scales, tests, or questionnaires in social sciences, psychology, education, and other fields. Reliability refers to the extent to which a scale produces consistent results across repeated measurements or multiple items measuring the same construct.
Conceptual Foundation
Internal Consistency
Internal consistency evaluates how well the items in a scale measure the same underlying construct. If items are highly correlated, it suggests they are measuring the same concept, which contributes to higher reliability.
For example:
A scale measuring motivation might include items like:
“I enjoy learning new things.”
“I am motivated to achieve my goals.”
“I find studying rewarding.”
If these items are highly interrelated, the scale has good internal consistency.
Definition of Cronbach’s Alpha
Cronbach’s Alpha quantifies internal consistency as a value between 0 and 1. Higher values indicate better reliability. The formula for α is:
Number of categories should be increased in order to count frequencies.
Warning in psych::alpha(motivation_data): Some items were negatively correlated with the first principal component and probably
should be reversed.
To do this, run the function again with the 'check.keys=TRUE' option
Some items ( Q1 Q2 Q4 ) were negatively correlated with the first principal component and
probably should be reversed.
To do this, run the function again with the 'check.keys=TRUE' option
Raw Alpha: The Cronbach’s Alpha for the current scale.
raw_alpha (-0.38)
음수의 알파 값은 내적 일관성이 전혀 없거나, 문항들이 서로 부정적인 관계를 가질 가능성을 나타냄
문항들이 측정하려는 동일한 개념(동일 구성 개념)을 반영하지 않거나, 측정 대상이 전혀 다른 경우에 나타남
Standardized Alpha: Adjusted for standardized item variances.
Item-Total Correlations: Correlation of each item with the total scale score.
Alpha If Deleted: The α value if a specific item is removed.
Improving Reliability
Increase the Number of Items: Add more items that measure the same construct.
Refine Items: Ensure items are clear, relevant, and unambiguous.
Remove Low-Quality Items: Exclude items that weaken the overall reliability (α).
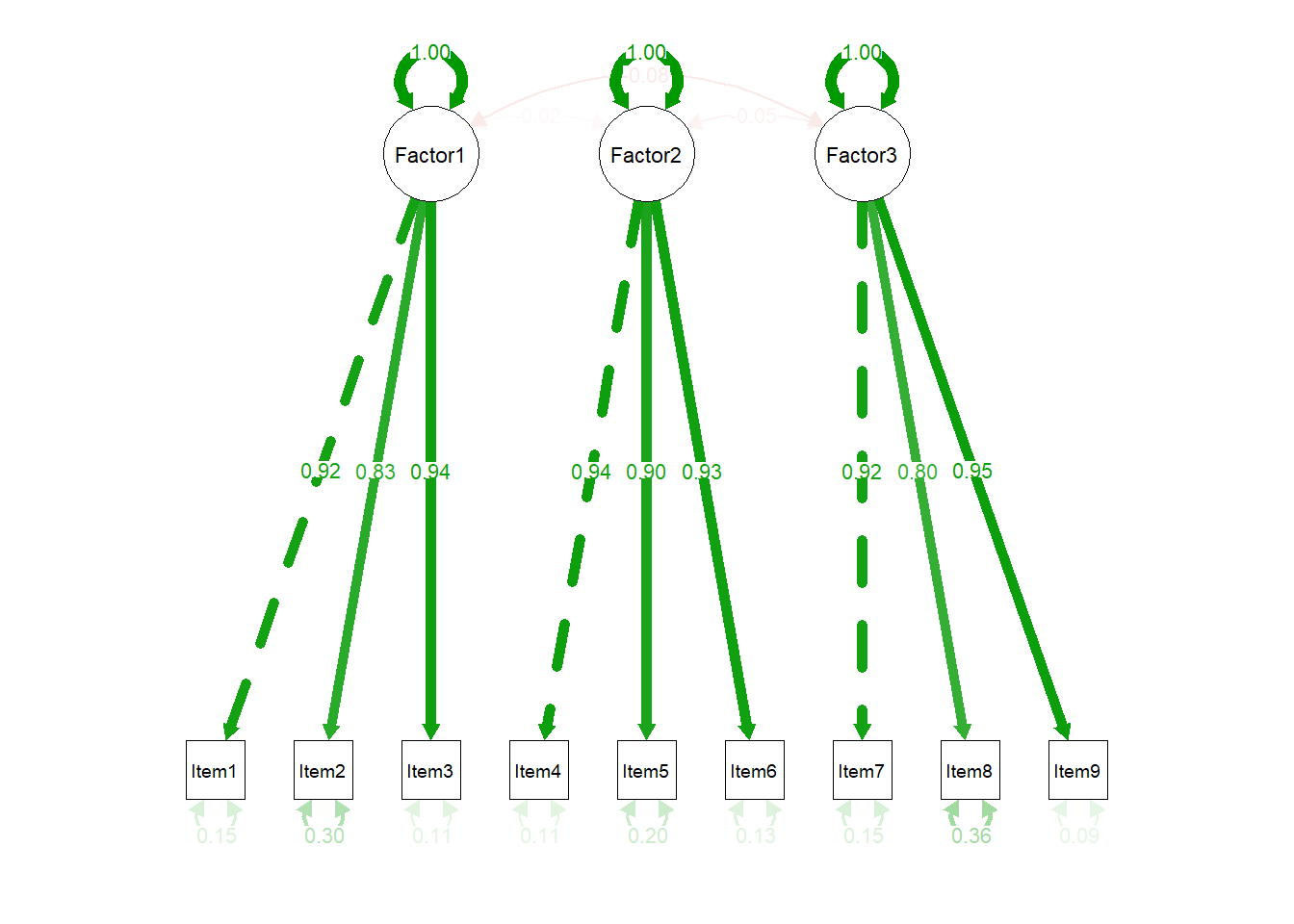
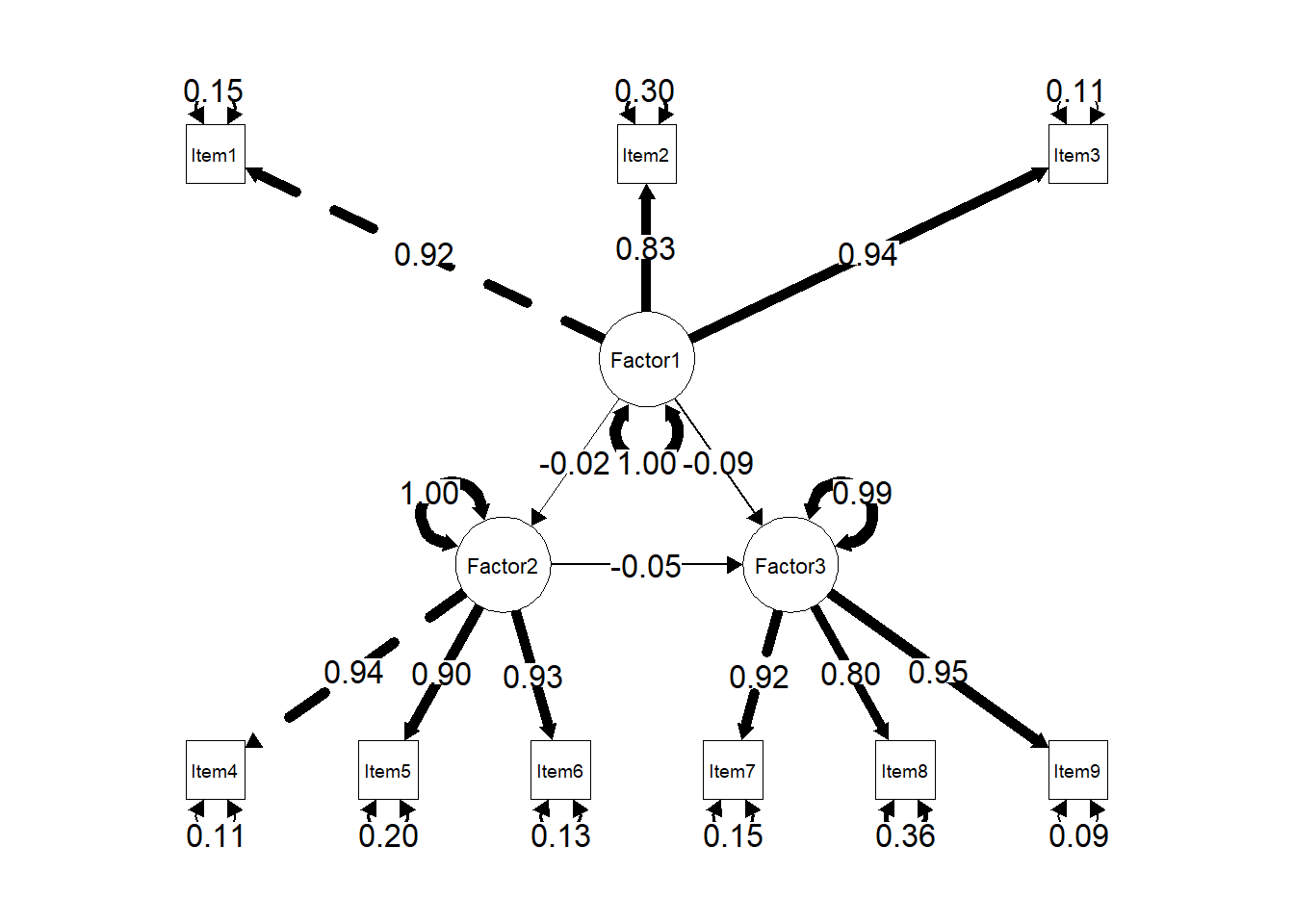
Confirmatory Factor Analysis (CFA)
Introduction
Confirmatory Factor Analysis (CFA) is a statistical technique used to test whether a hypothesized measurement model fits the observed data. Unlike Exploratory Factor Analysis (EFA), which identifies underlying factor structures without prior assumptions, CFA is hypothesis-driven and requires the researcher to specify the relationships between observed variables and latent factors before analysis.
CFA is widely used in psychology, education, and social sciences to validate measurement scales, confirm theoretical constructs, and ensure the reliability of instruments.
Key Concepts in CFA
1. Latent Variables
Latent variables are unobserved constructs that are inferred from multiple observed variables. For example:
Motivation might be a latent variable inferred from survey items like “I enjoy studying” and “I set academic goals.”
2. Observed Variables (Indicators)
These are measurable variables that serve as proxies for the latent variable. In CFA, each observed variable is expected to load on a specific latent factor.
3. Factor Loadings
Factor loadings quantify the relationship between observed variables and their underlying latent factor. Higher loadings indicate stronger relationships.
4. Measurement Errors
CFA explicitly models measurement error for each observed variable, improving the accuracy of parameter estimates compared to traditional methods.
The CFA Model
The CFA model is typically represented as:
\[
X = \Lambda \xi + \delta
\]
Where:
X: Vector of observed variables.
Λ: Matrix of factor loadings.
ξ: Vector of latent variables.
δ: Vector of measurement errors.
Model Fit Indices in CFA
Several indices are used to assess the goodness of fit of a CFA model:
Chi-Square:
Tests the null hypothesis that the model fits the data perfectly.
Smaller, non-significant values indicate a good fit.
Sensitive to sample size.
CFI (Comparative Fit Index):
Compares the fit of the hypothesized model to a null model.
Values > 0.90 indicate good fit; > 0.95 indicates excellent fit.
TLI (Tucker-Lewis Index):
Adjusts for model complexity.
Values > 0.90 indicate good fit.
RMSEA (Root Mean Square Error of Approximation):
Measures the discrepancy between the model and the data per degree of freedom.
# semPaths() 함수 수정: 경로의 투명도 및 색상 조정semPaths(object = sem_fit, # SEM 모델 객체what ="std", # 표준화된 경로 계수 표시layout ="tree", # 트리 레이아웃edge.label.cex =1.2, # 경로 레이블 크기 (더 크게)edge.color ="black", # 선 색상 지정edge.width =1, # 선의 두께residuals =TRUE, # 잔차 포함intercepts =FALSE, # 절편 제거fade =FALSE, # 투명도 조정 (FALSE로 설정하여 선을 더 선명하게)nCharNodes =0# 노드 이름의 길이 제한 없음)
Exploratory Factor Analysis (EFA)
데이터가 스스로 말하도록 해서 ’숨겨진 구조(잠재 요인)’를 찾는 통계 기법.
설문 문항들이 어떤 요인들로 자연스럽게 묶이는지를 사전에 가정하지 않고 탐색하는 방법.
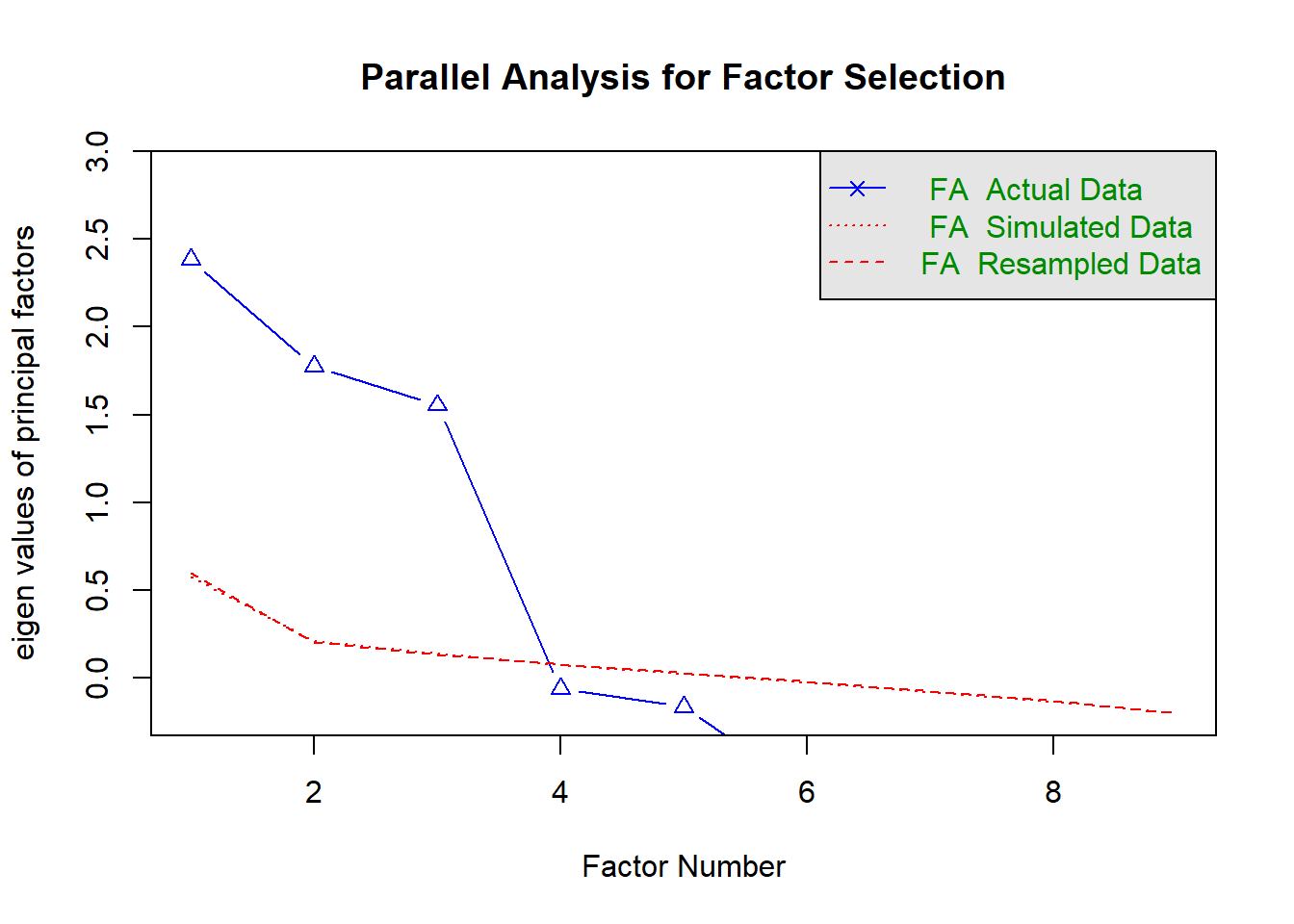
# -------------------------------------------------# 1. Load psych package# -------------------------------------------------library(psych)# -------------------------------------------------# 2. Determine the number of factors# - Parallel analysis (가장 추천되는 방법)# -------------------------------------------------fa.parallel(observed_data, fa ="fa", # factor analysisn.iter =100, # bootstrap iterationsshow.legend =TRUE,main ="Parallel Analysis for Factor Selection")
Warning in fa.stats(r = r, f = f, phi = phi, n.obs = n.obs, np.obs = np.obs, :
The estimated weights for the factor scores are probably incorrect. Try a
different factor score estimation method.
Warning in fa.stats(r = r, f = f, phi = phi, n.obs = n.obs, np.obs = np.obs, :
The estimated weights for the factor scores are probably incorrect. Try a
different factor score estimation method.
Parallel analysis suggests that the number of factors = 3 and the number of components = NA
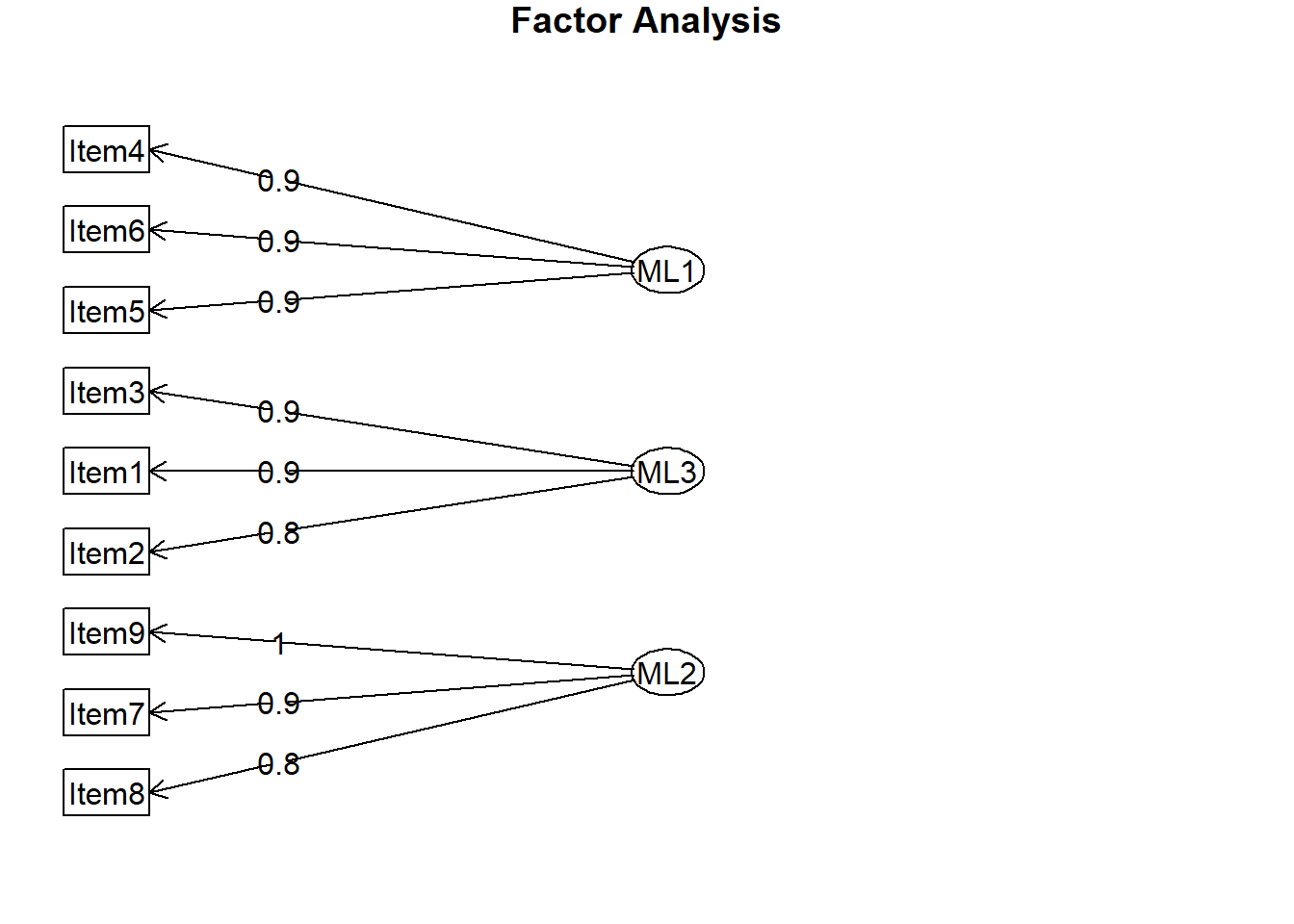
# -------------------------------------------------# 3. Run EFA (Exploratory Factor Analysis)# - 여기서는 3개 요인 지정 (위에서 우리가 생성한 구조)# - rotation = "promax": oblique rotation (요인 상관 허용)# -------------------------------------------------efa_result <-fa(observed_data, nfactors =3, fm ="ml", # maximum likelihood (추천)rotate ="promax")
Factor Analysis using method = ml
Call: fa(r = observed_data, nfactors = 3, rotate = "promax", fm = "ml")
Standardized loadings (pattern matrix) based upon correlation matrix
ML1 ML3 ML2 h2 u2 com
Item1 0.039 0.928 0.028 0.856 0.1438 1.01
Item2 -0.019 0.830 -0.032 0.698 0.3023 1.00
Item3 -0.018 0.940 0.008 0.883 0.1167 1.00
Item4 0.945 -0.011 0.013 0.892 0.1077 1.00
Item5 0.896 0.014 -0.013 0.804 0.1965 1.00
Item6 0.934 -0.004 -0.001 0.872 0.1279 1.00
Item7 -0.024 -0.008 0.916 0.844 0.1562 1.00
Item8 0.010 -0.033 0.793 0.636 0.3640 1.00
Item9 0.011 0.049 0.962 0.916 0.0841 1.01
ML1 ML3 ML2
SS loadings 2.570 2.437 2.394
Proportion Var 0.286 0.271 0.266
Cumulative Var 0.286 0.556 0.822
Proportion Explained 0.347 0.329 0.323
Cumulative Proportion 0.347 0.677 1.000
With factor correlations of
ML1 ML3 ML2
ML1 1.000 -0.022 -0.049
ML3 -0.022 1.000 -0.115
ML2 -0.049 -0.115 1.000
Mean item complexity = 1
Test of the hypothesis that 3 factors are sufficient.
df null model = 36 with the objective function = 7.799 with Chi Square = 2302.136
df of the model are 12 and the objective function was 0.027
The root mean square of the residuals (RMSR) is 0.005
The df corrected root mean square of the residuals is 0.009
The harmonic n.obs is 300 with the empirical chi square 0.592 with prob < 1
The total n.obs was 300 with Likelihood Chi Square = 7.975 with prob < 0.787
Tucker Lewis Index of factoring reliability = 1.0054
RMSEA index = 0 and the 90 % confidence intervals are 0 0.0395
BIC = -60.47
Fit based upon off diagonal values = 1
Measures of factor score adequacy
ML1 ML3 ML2
Correlation of (regression) scores with factors 0.975 0.970 0.973
Multiple R square of scores with factors 0.951 0.941 0.948
Minimum correlation of possible factor scores 0.901 0.881 0.895
The basic idea behind k-means clustering consists of defining clusters so that the total intra-cluster variation (known as total within-cluster variation) is minimized. There are several k-means algorithms available. The standard algorithm is the Hartigan-Wong algorithm (Hartigan and Wong 1979), which defines the total within-cluster variation as the sum of squared distances Euclidean distances between items and the corresponding centroid
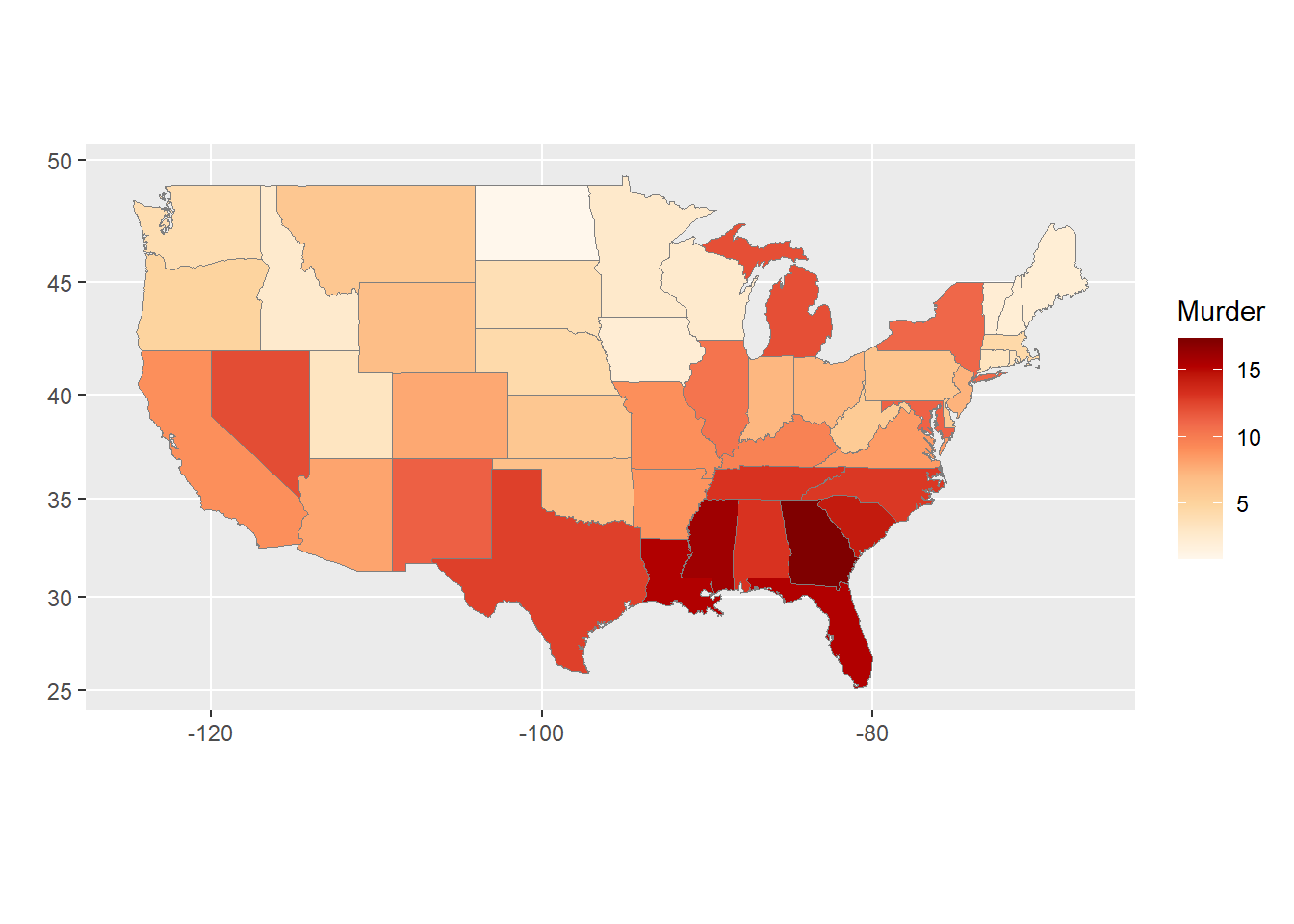
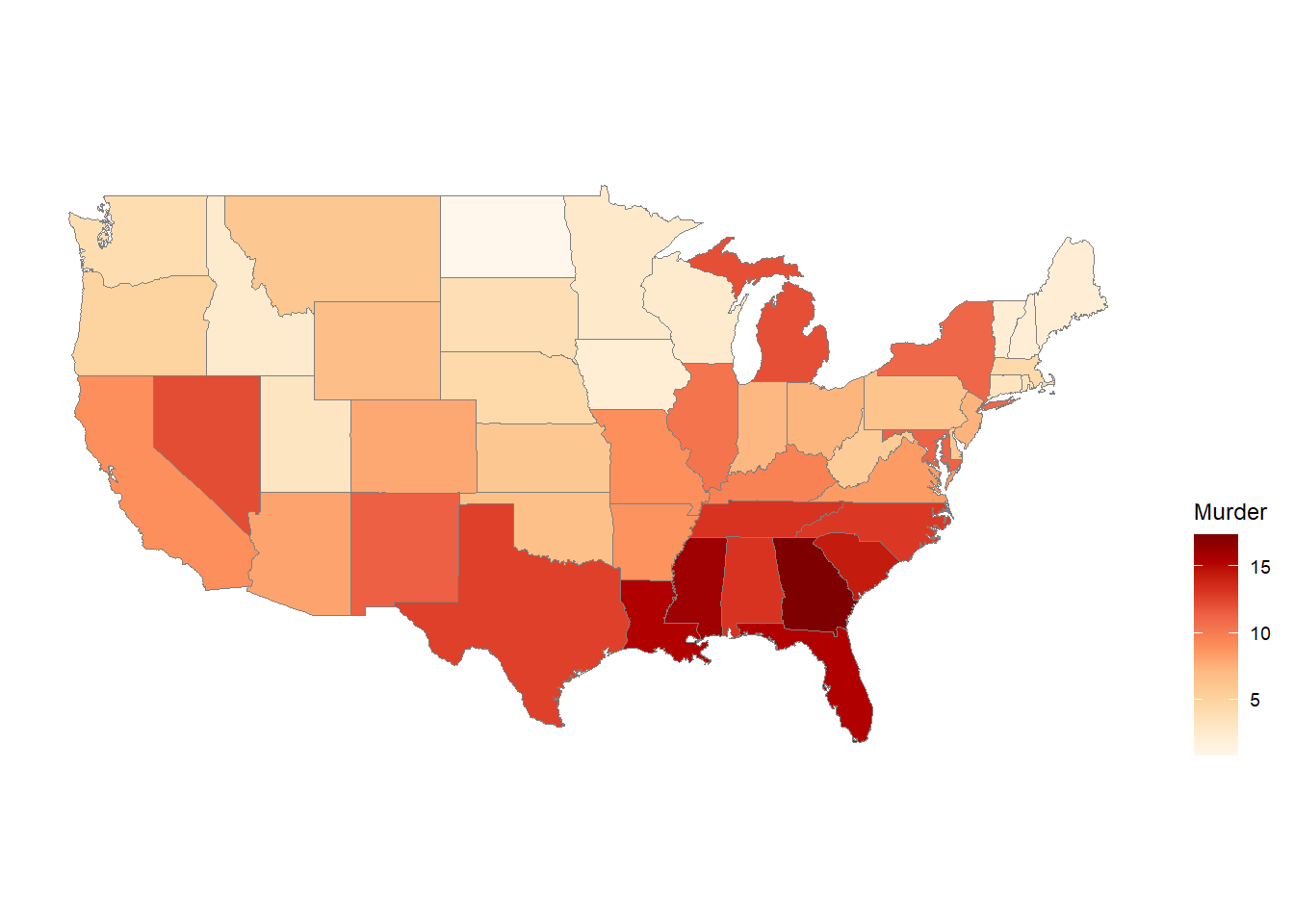
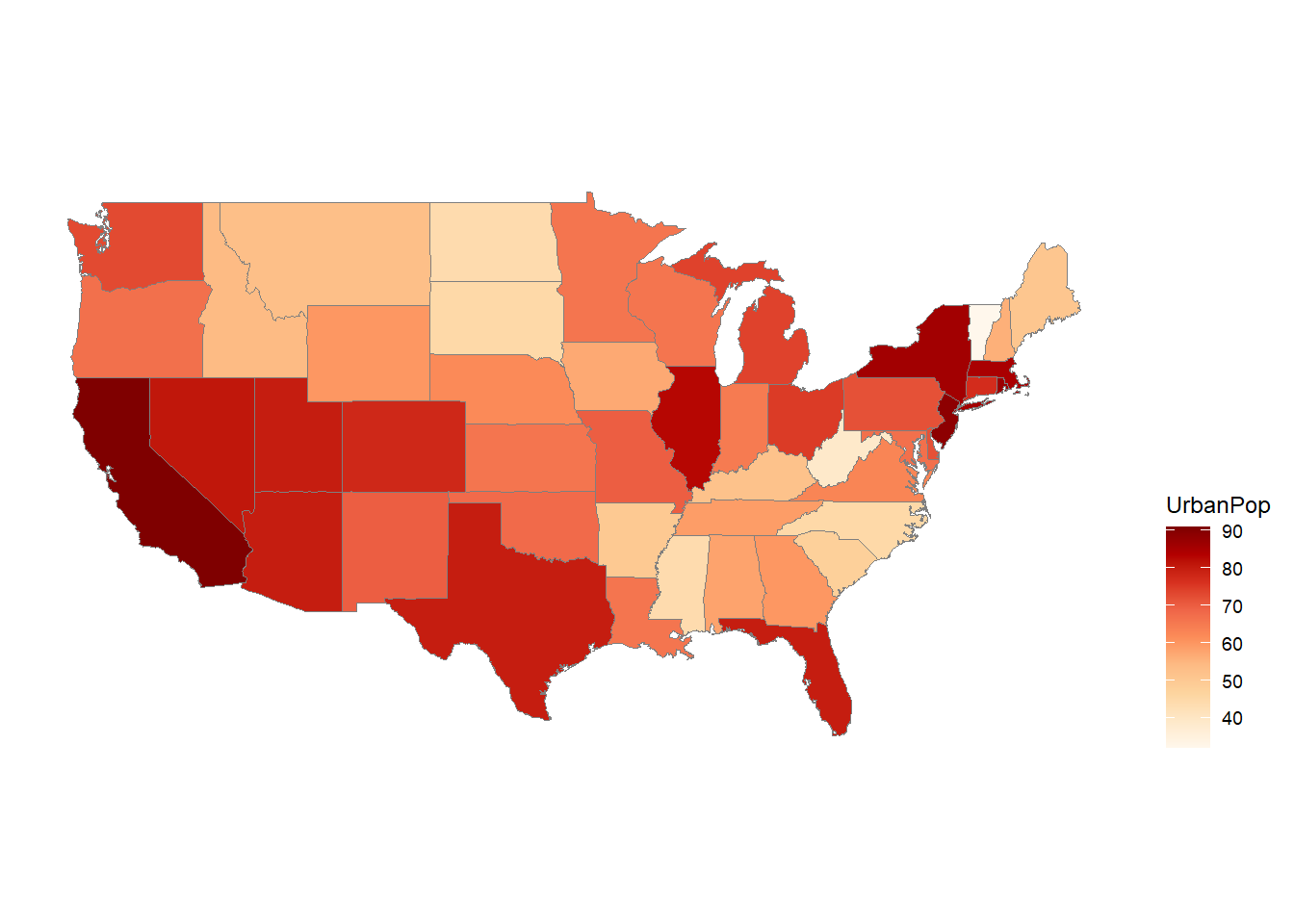
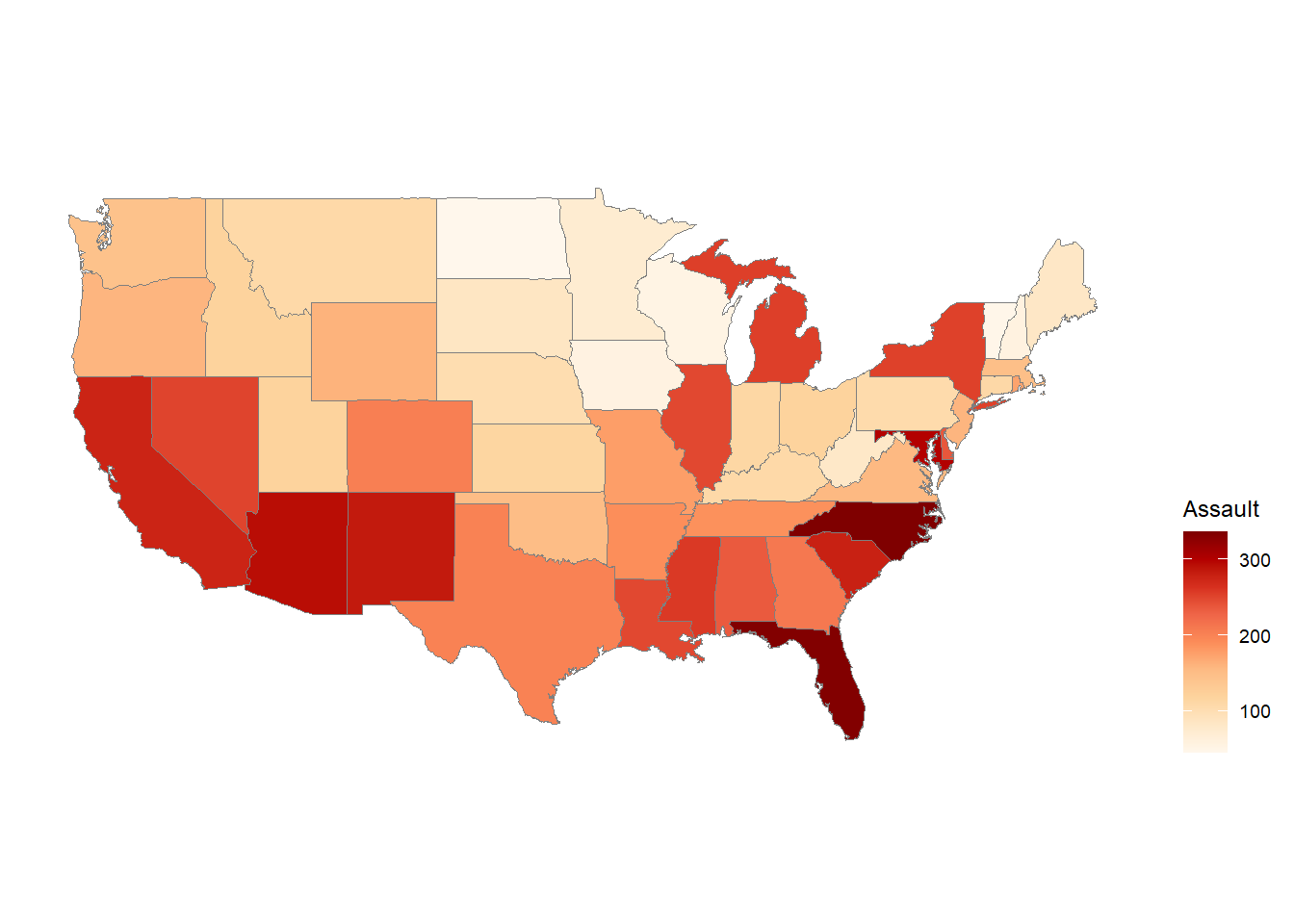
The USArrests dataset is a built-in dataset in R that contains data on crime rates (number of arrests per 100,000 residents) in the United States in 1973. The dataset has 50 observations, corresponding to the 50 US states, and 4 variables:
Murder: Murder arrests (number of arrests for murder per 100,000 residents).
Assault: Assault arrests (number of arrests for assault per 100,000 residents).
UrbanPop: Urban population (percentage of the population living in urban areas).
Rape: Rape arrests (number of arrests for rape per 100,000 residents).
The states_map <- map_data("state") code is used to create a dataframe that contains map data for the 50 states in the United States.
The map_data() function is from the ggplot2 package, and it returns a dataframe that contains latitude and longitude coordinates for the boundaries of each state, along with additional information that can be used to plot the map.
The argument to the map_data() function is the name of the region for which to retrieve the map data. In this case, the argument is "state", which indicates that we want map data for the 50 states in the US.
The resulting states_map dataframe contains the following columns:
long: A vector of longitudes representing the boundaries of the state.
lat: A vector of latitudes representing the boundaries of the state.
group: An integer indicating the group to which each point belongs. This is used to group the points together when plotting the map.
order: An integer indicating the order in which the points should be plotted.
region: A character string indicating the name of the state.
subregion: A character string indicating the name of a subregion within the state, if applicable. This is usually NA for the state maps.
states_map <-map_data("state")head(states_map)
long lat group order region subregion
1 -87.46201 30.38968 1 1 alabama <NA>
2 -87.48493 30.37249 1 2 alabama <NA>
3 -87.52503 30.37249 1 3 alabama <NA>
4 -87.53076 30.33239 1 4 alabama <NA>
5 -87.57087 30.32665 1 5 alabama <NA>
6 -87.58806 30.32665 1 6 alabama <NA>
The code library(ggiraphExtra) loads the ggiraphExtra package, which extends the functionality of the ggplot2 package to allow for interactive graphics in R.
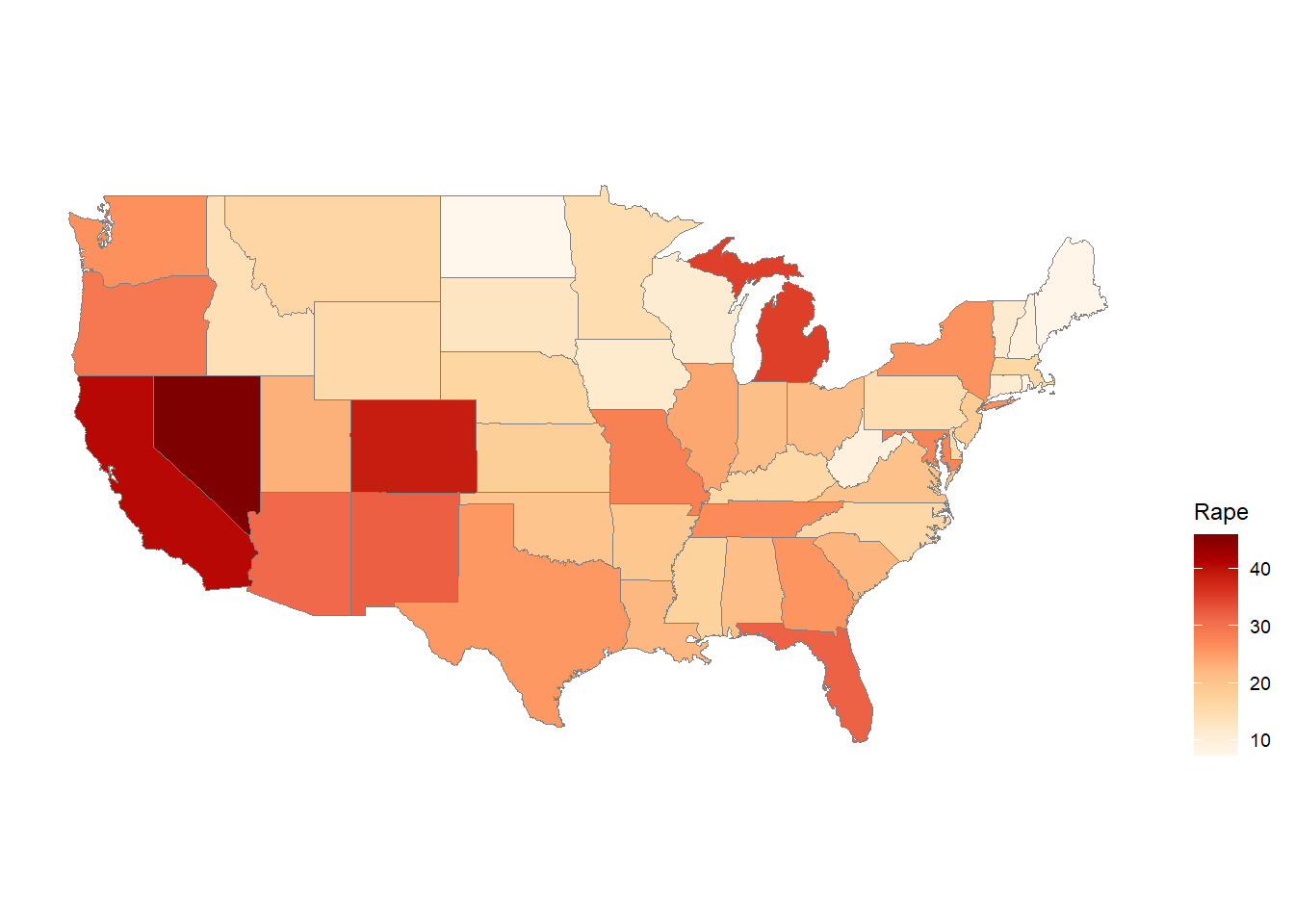
The ggChoropleth() function is from the ggiraphExtra package and is used to create a choropleth map in which each state is colored according to its value of a specified variable.
The first argument to ggChoropleth() is the data frame containing the data to be plotted, which is crime in this case.
The second argument is the aes() function, which is used to map variables in the data frame to visual properties of the plot. The fill aesthetic is used to specify that the color of each state should be determined by the value of the Murder variable in the crime data frame. The map_id aesthetic is used to specify that each state should be identified by its name, which is found in the state variable in the crime data frame.
The third argument is the map argument, which specifies the data frame containing the map data. In this case, the states_map data frame is used, which was created earlier using the map_data() function.
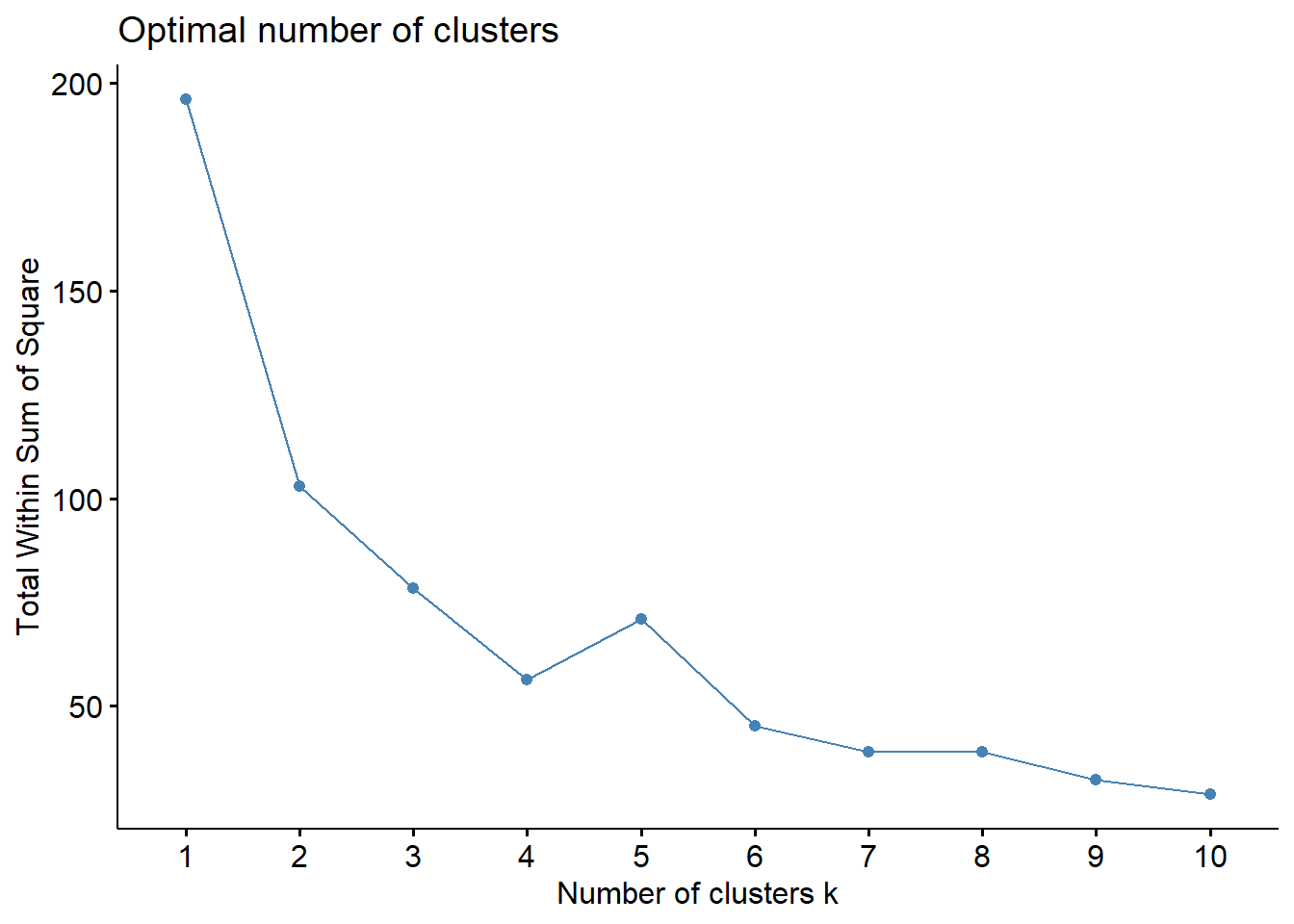
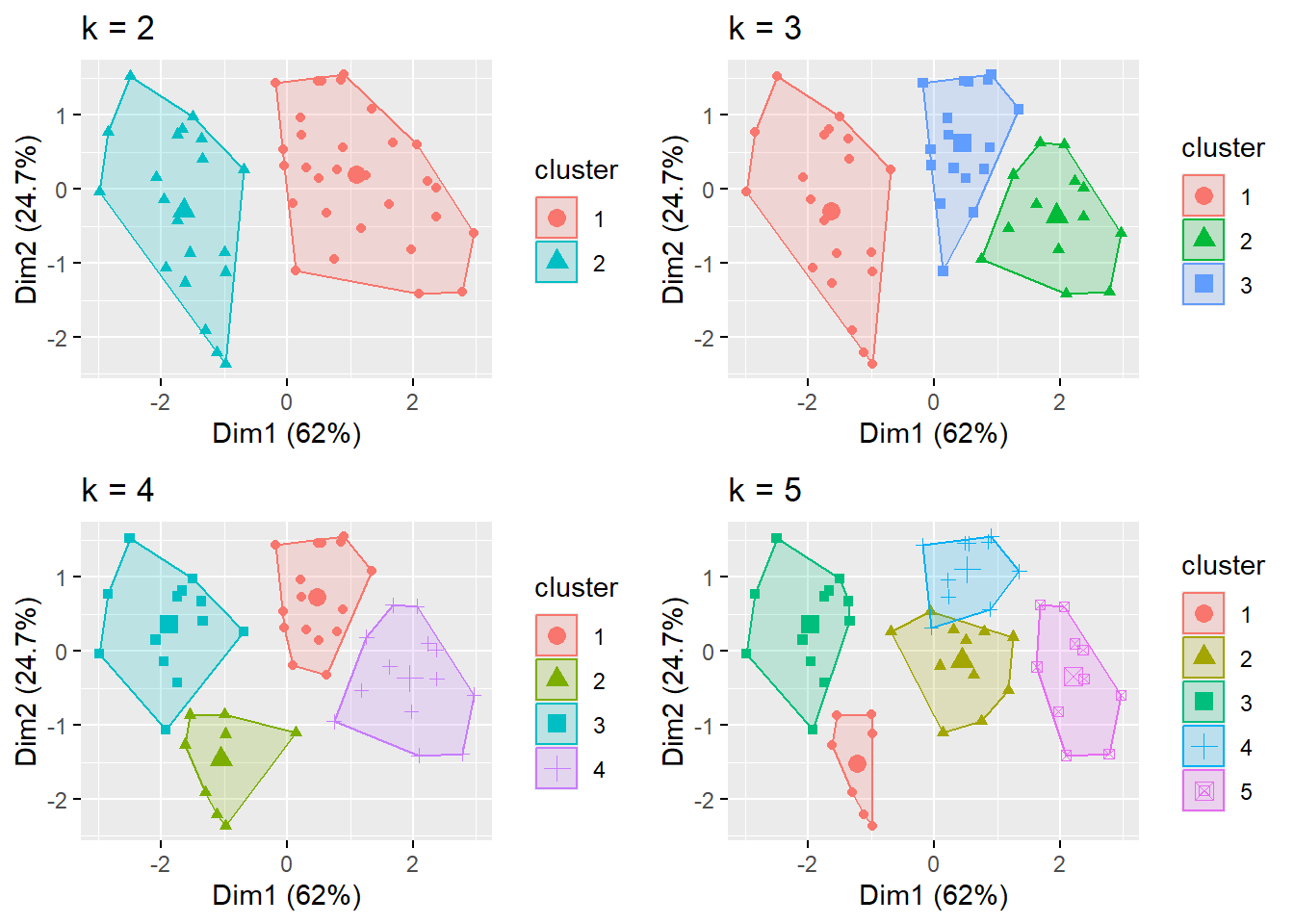
This code uses the fviz_nbclust() function from the factoextra package in R to determine the optimal number of clusters to use in a K-means clustering analysis.
The first argument of fviz_nbclust() is the data frame df that contains the variables to be used in the clustering analysis.
The second argument is the clustering function kmeans that specifies the algorithm to be used for clustering.
The third argument method specifies the method to be used to determine the optimal number of clusters. In this case, two methods are used:
"wss": Within-cluster sum of squares. This method computes the sum of squared distances between each observation and its assigned cluster center, and then adds up these values across all clusters. The goal is to find the number of clusters that minimize the within-cluster sum of squares.
"silhouette": Silhouette width. This method computes a silhouette width for each observation, which measures how similar the observation is to its own cluster compared to other clusters. The goal is to find the number of clusters that maximize the average silhouette width across all observations.
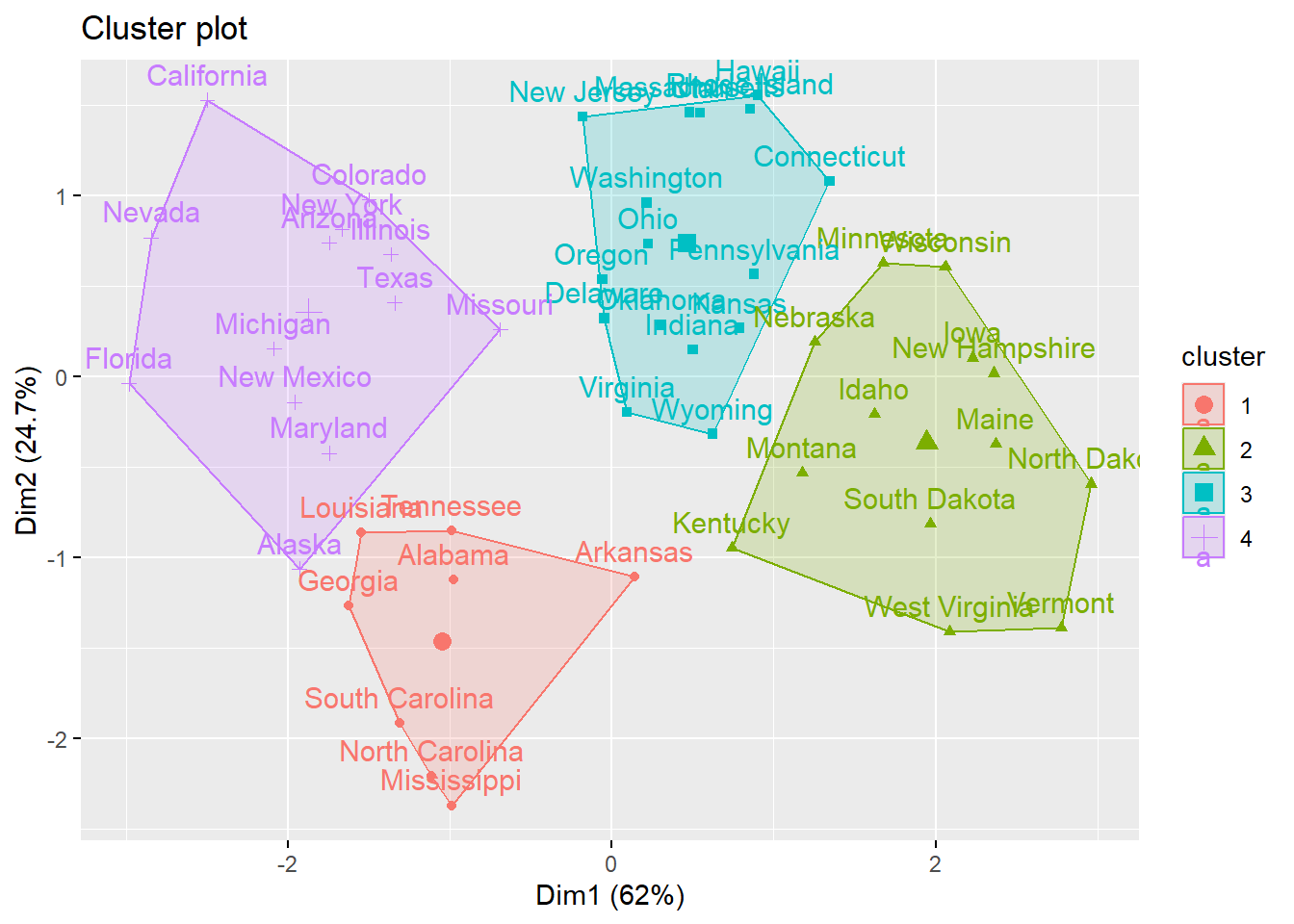
Let’s run unsupervised clustering given k=4
# Compute k-means with k = 4set.seed(123)km.res <-kmeans(df, 4, nstart =25)
As the final result of k-means clustering result is sensitive to the random starting assignments, we specify nstart = 25. This means that R will try 25 different random starting assignments and then select the best results corresponding to the one with the lowest within cluster variation. The default value of nstart in R is one. But, it’s strongly recommended to compute k-means clustering with a large value of nstart such as 25 or 50, in order to have a more stable result.
Print the result
# Print the resultsprint(km.res)
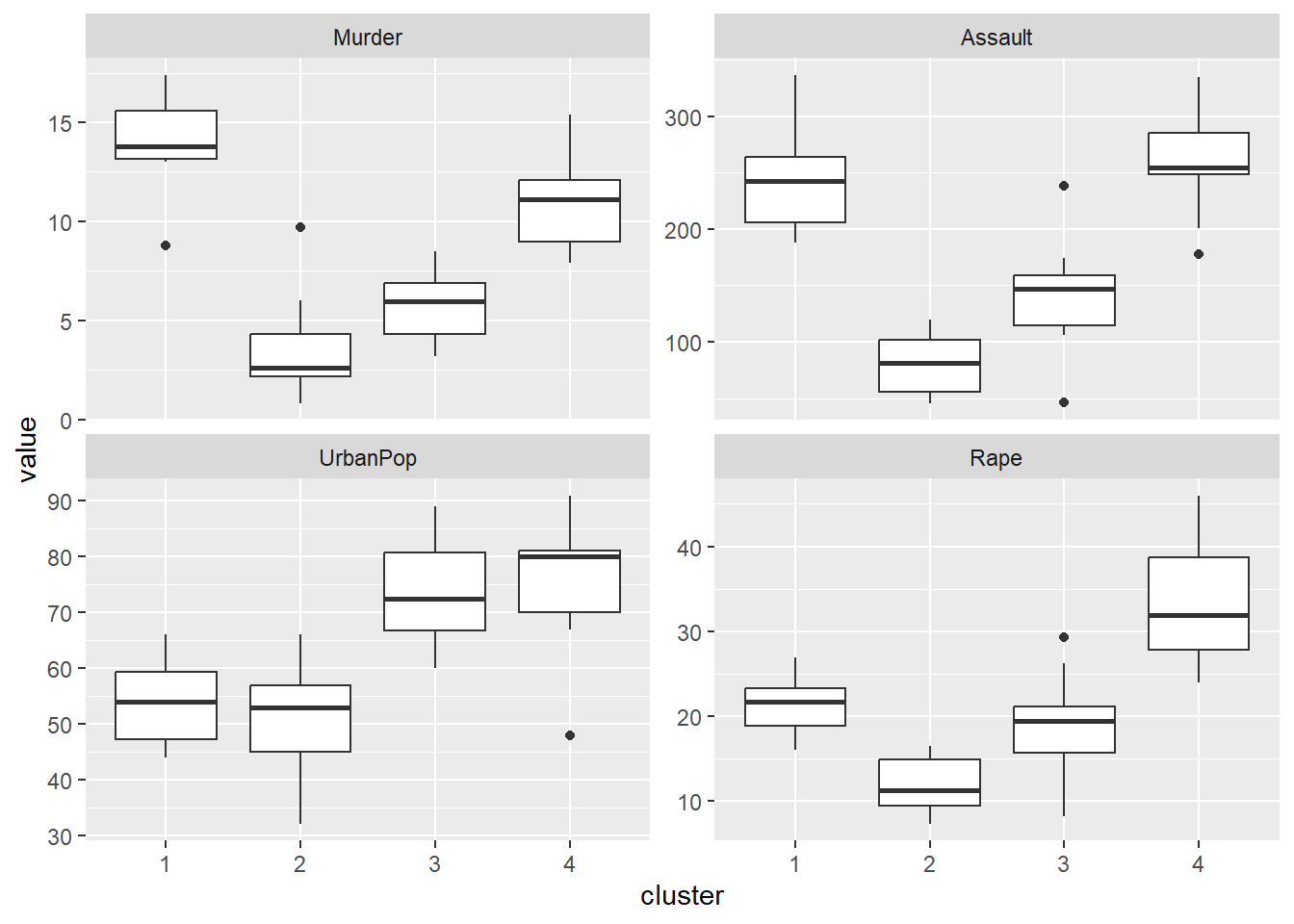
K-means clustering with 4 clusters of sizes 8, 13, 16, 13
Cluster means:
Murder Assault UrbanPop Rape
1 1.4118898 0.8743346 -0.8145211 0.01927104
2 -0.9615407 -1.1066010 -0.9301069 -0.96676331
3 -0.4894375 -0.3826001 0.5758298 -0.26165379
4 0.6950701 1.0394414 0.7226370 1.27693964
Clustering vector:
Alabama Alaska Arizona Arkansas California
1 4 4 1 4
Colorado Connecticut Delaware Florida Georgia
4 3 3 4 1
Hawaii Idaho Illinois Indiana Iowa
3 2 4 3 2
Kansas Kentucky Louisiana Maine Maryland
3 2 1 2 4
Massachusetts Michigan Minnesota Mississippi Missouri
3 4 2 1 4
Montana Nebraska Nevada New Hampshire New Jersey
2 2 4 2 3
New Mexico New York North Carolina North Dakota Ohio
4 4 1 2 3
Oklahoma Oregon Pennsylvania Rhode Island South Carolina
3 3 3 3 1
South Dakota Tennessee Texas Utah Vermont
2 1 4 3 2
Virginia Washington West Virginia Wisconsin Wyoming
3 3 2 2 3
Within cluster sum of squares by cluster:
[1] 8.316061 11.952463 16.212213 19.922437
(between_SS / total_SS = 71.2 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
The printed output displays: the cluster means or centers: a matrix, which rows are cluster number (1 to 4) and columns are variables the clustering vector: A vector of integers (from 1:k) indicating the cluster to which each point is allocated
If you want to add the point classifications to the original data, use this:
str(km.res)
List of 9
$ cluster : Named int [1:50] 1 4 4 1 4 4 3 3 4 1 ...
..- attr(*, "names")= chr [1:50] "Alabama" "Alaska" "Arizona" "Arkansas" ...
$ centers : num [1:4, 1:4] 1.412 -0.962 -0.489 0.695 0.874 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:4] "1" "2" "3" "4"
.. ..$ : chr [1:4] "Murder" "Assault" "UrbanPop" "Rape"
$ totss : num 196
$ withinss : num [1:4] 8.32 11.95 16.21 19.92
$ tot.withinss: num 56.4
$ betweenss : num 140
$ size : int [1:4] 8 13 16 13
$ iter : int 2
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
km.res$cluster
Alabama Alaska Arizona Arkansas California
1 4 4 1 4
Colorado Connecticut Delaware Florida Georgia
4 3 3 4 1
Hawaii Idaho Illinois Indiana Iowa
3 2 4 3 2
Kansas Kentucky Louisiana Maine Maryland
3 2 1 2 4
Massachusetts Michigan Minnesota Mississippi Missouri
3 4 2 1 4
Montana Nebraska Nevada New Hampshire New Jersey
2 2 4 2 3
New Mexico New York North Carolina North Dakota Ohio
4 4 1 2 3
Oklahoma Oregon Pennsylvania Rhode Island South Carolina
3 3 3 3 1
South Dakota Tennessee Texas Utah Vermont
2 1 4 3 2
Virginia Washington West Virginia Wisconsin Wyoming
3 3 2 2 3
Create a new data frame including cluster information