Libraries are software that collects R functions developed for specific fields.
E.g.) ggplot2 is a collection of functions that visualize your data neatly and consistently
E.g.) gapminder is a collection of functions needed to utilize gapminder data, which gathers population, GDP per capita, and life expectancy in five years from 1952 to 2007.
R is so powerful and popular because of its huge library
If you access the CRAN site, you will see that it is still being added.
[Packages] menu: see all libraries provided by R [Task Views] menu: Introduce libraries field by field
When using it, attach it using the library function
Library installation saves library files to your hard disk
Library Attachment loads it from Hard Disk to Main Memory
Data for example..
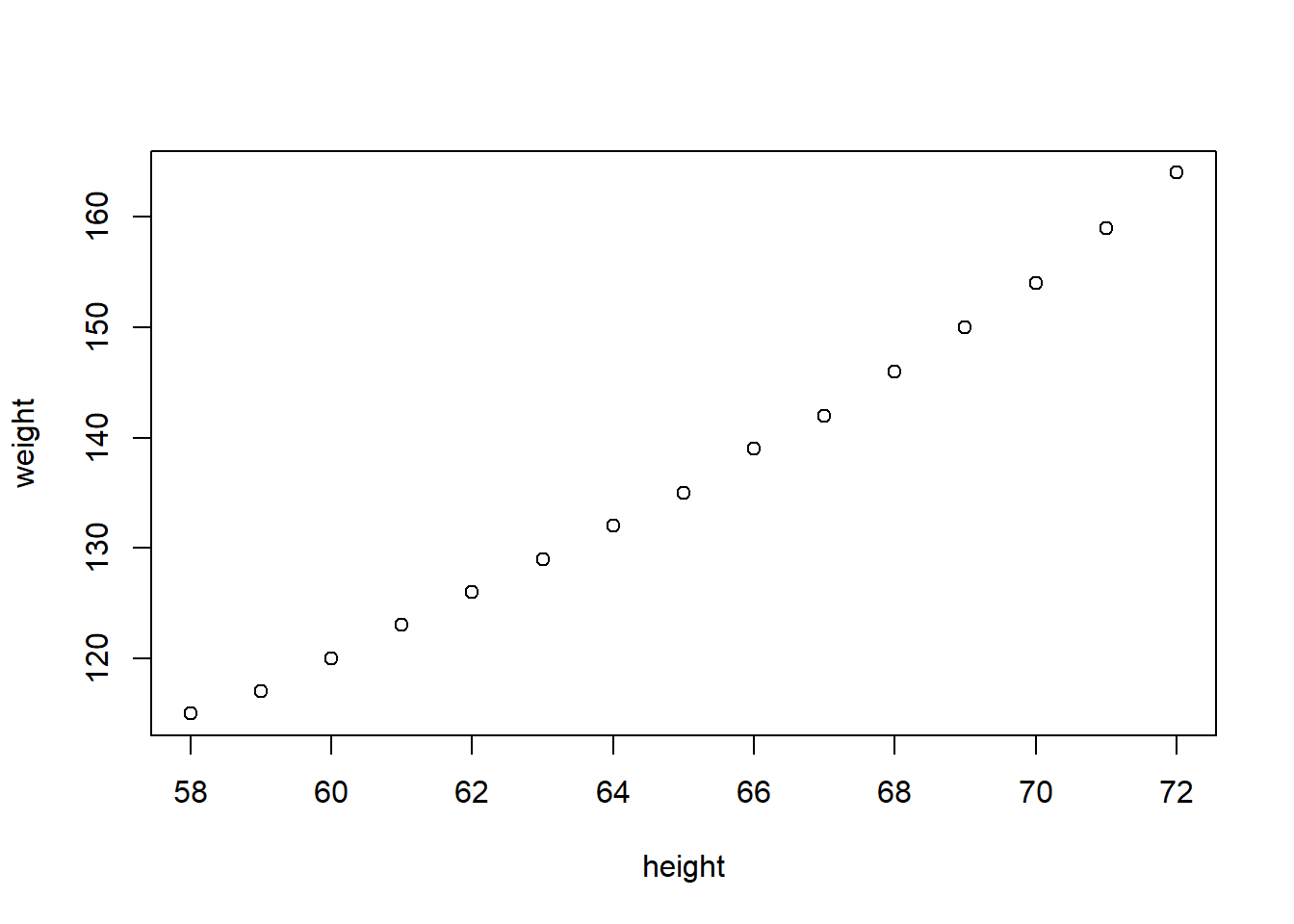
Lovely iris data
In 1936, Edger Anderson collected irises in the Gaspe Peninsula in eastern Canada.
Collect 50 from each three species(setosa, versicolor, verginica) on the same day
The same person measures the width and length of the petals and sepals with the same ruler
Has been famous since Statistician Professor Ronald Fisher published a paper with this data and is still widely used.
total_bill tip sex smoker day time size
1 16.99 1.01 Female No Sun Dinner 2
2 10.34 1.66 Male No Sun Dinner 3
3 21.01 3.50 Male No Sun Dinner 3
4 23.68 3.31 Male No Sun Dinner 2
5 24.59 3.61 Female No Sun Dinner 4
6 25.29 4.71 Male No Sun Dinner 4
7 8.77 2.00 Male No Sun Dinner 2
8 26.88 3.12 Male No Sun Dinner 4
9 15.04 1.96 Male No Sun Dinner 2
10 14.78 3.23 Male No Sun Dinner 2
Interpreting the first sample, it was shown that two people had dinner on Sunday, no smokers, and a $1.01 tip at the table where a woman paid the total $16.99.
Step 2: Exploratory Data Analysis (EDA)
summary function to check the summary statistics
How to explain the summary statistics below?
summary(tips)
total_bill tip sex smoker
Min. : 3.07 Min. : 1.000 Length:244 Length:244
1st Qu.:13.35 1st Qu.: 2.000 Class :character Class :character
Median :17.80 Median : 2.900 Mode :character Mode :character
Mean :19.79 Mean : 2.998
3rd Qu.:24.13 3rd Qu.: 3.562
Max. :50.81 Max. :10.000
day time size
Length:244 Length:244 Min. :1.00
Class :character Class :character 1st Qu.:2.00
Mode :character Mode :character Median :2.00
Mean :2.57
3rd Qu.:3.00
Max. :6.00
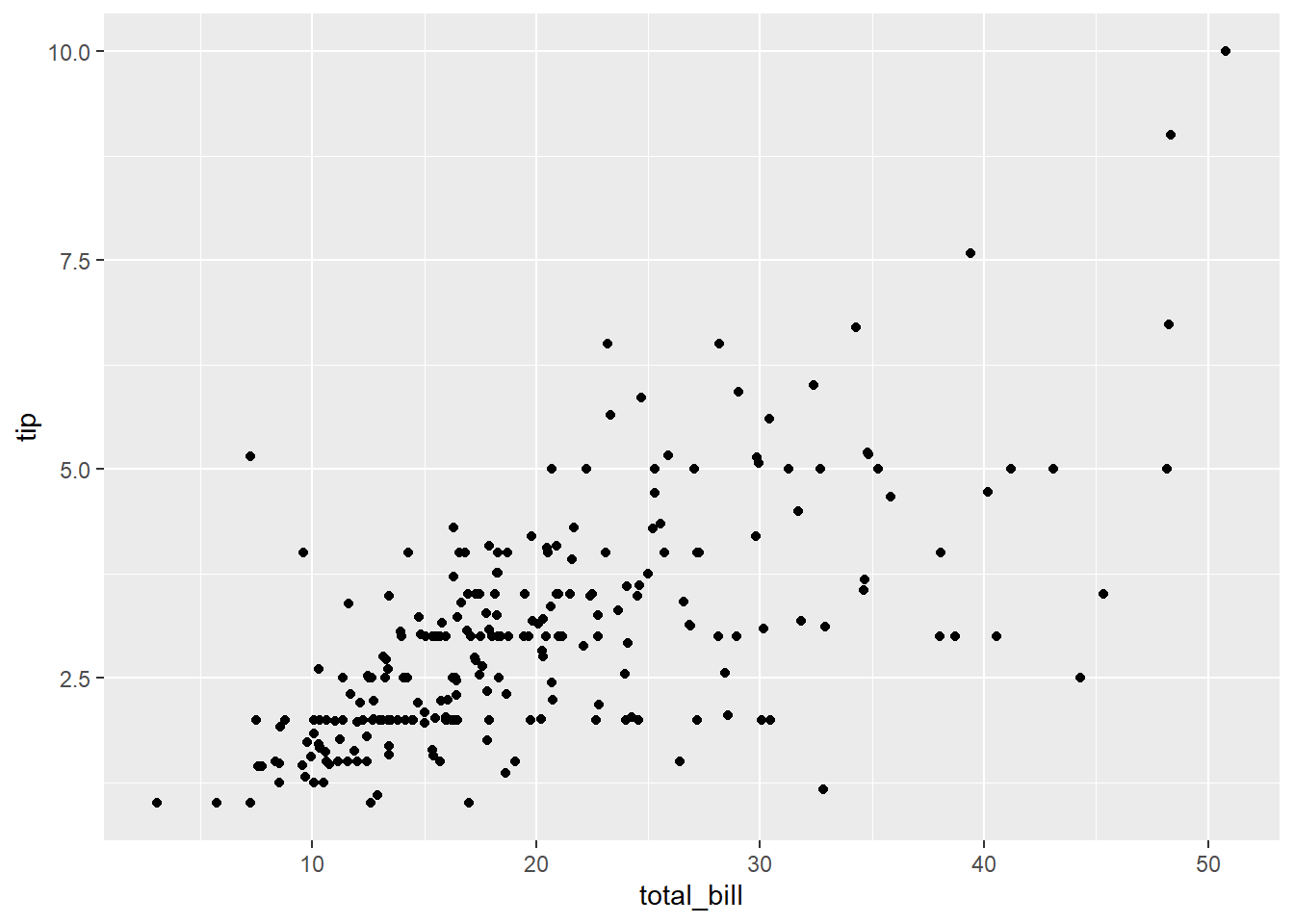
This statistic summary doesn’t reveal the effect of day or gender on the tip, so let’s explore it further with visualization.
Attach dplyr and ggplot2 libraries (for now just run it and study the meaning)
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(ggplot2)
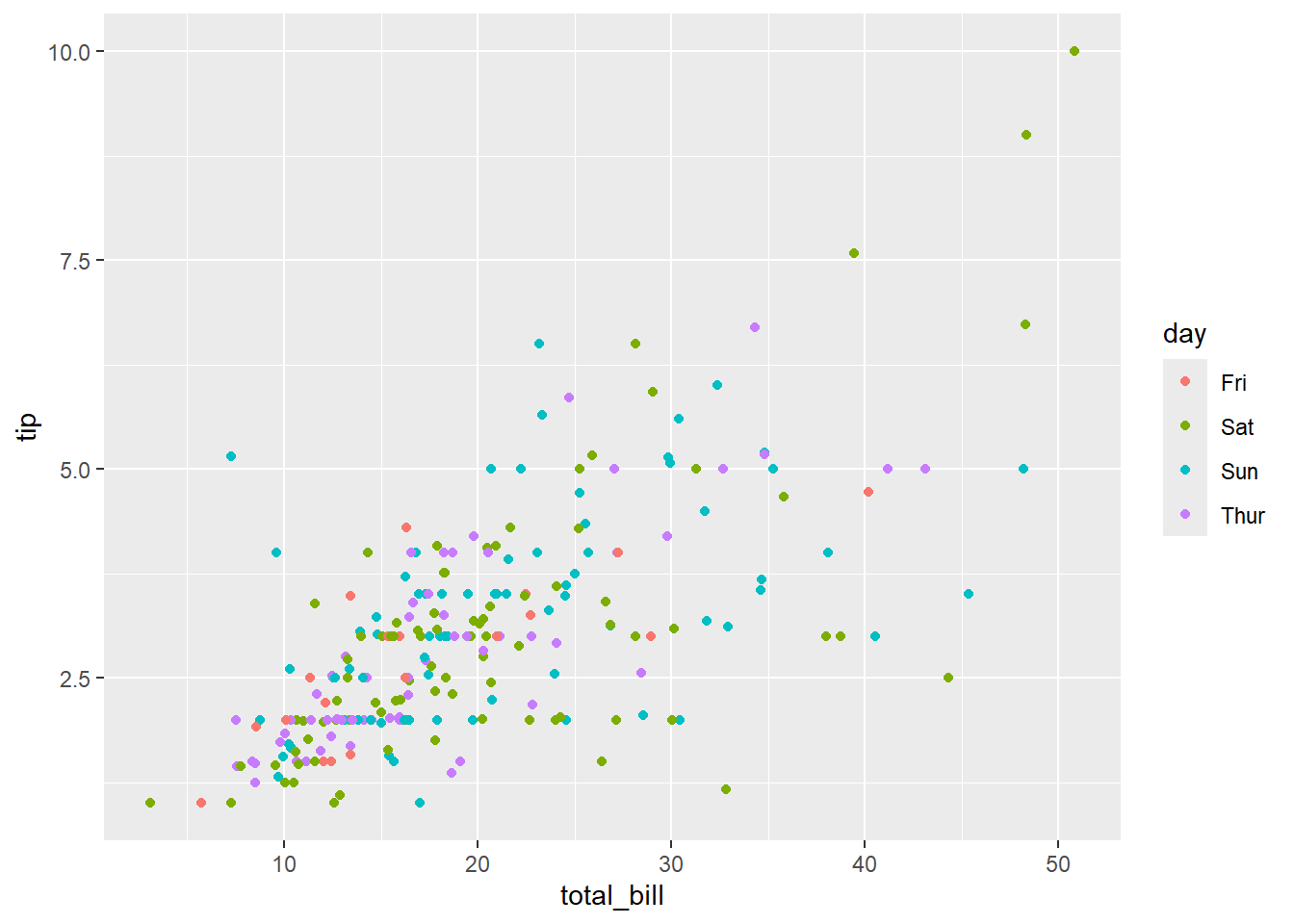
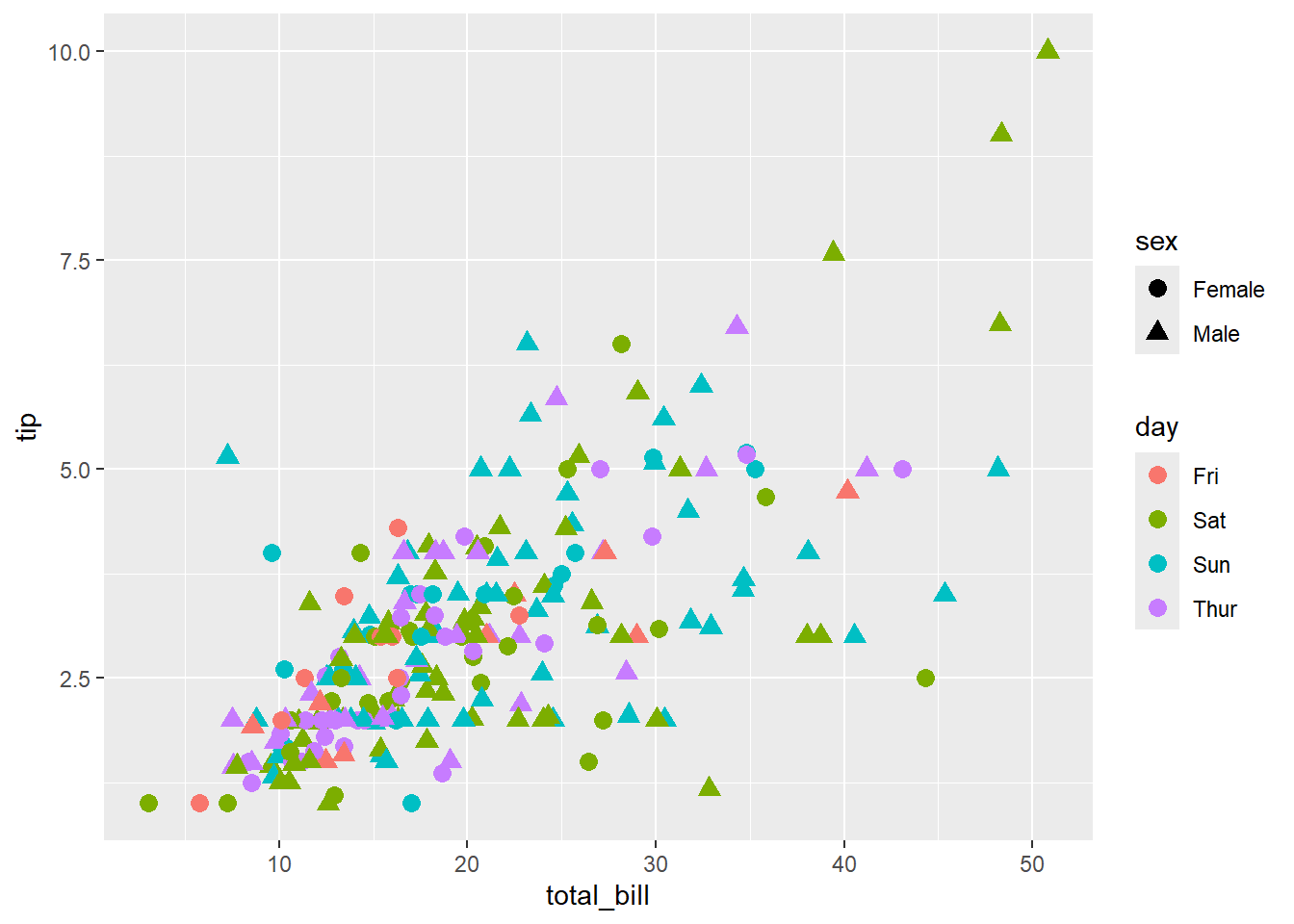
What do you see in the figures below?
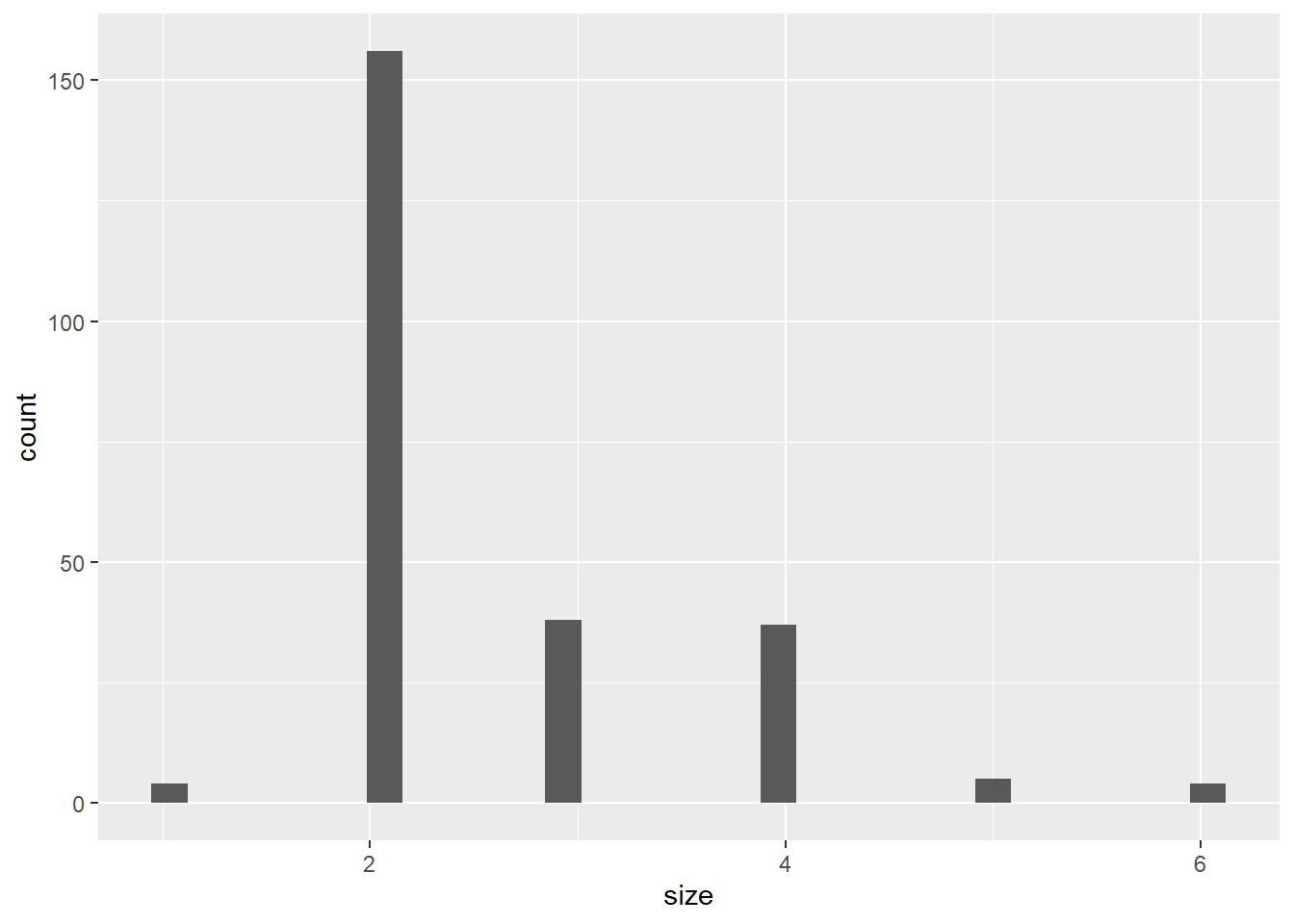
Distribution of fellow persons in a table
tips %>%ggplot(aes(size)) +geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Limitations of Exploratory Data Analysis: You can design a strategy to make more money, but you can’t predict exactly how much more income will come from the new strategy.
Modeling allows predictions
Create future financial portfolios
E.g.) Know how much your income will increase as fellows in a table grow, and how much your income will change when paying people’s gender changes
Setup your project!
Create a new project
*.Rproj
*.R
getwd()
Variable and Object
An object in R is a data structure used for storing data: Everything in R is an object, including functions, numbers, character strings, vectors, and lists. Each object has attributes such as its type (e.g., integer, numeric, character), its length, and often its dimensions. Objects can be complex structures, like data frames that hold tabular data, or simpler structures like a single numeric value or vector.
A variable in R is a name that you assign to an object so that you can refer to it later in your code. When you assign data to a variable, you are effectively labeling that data with a name that you can use to call up the object later on.
Here’s a simple example in R:
my_vector <-c(1, 2, 3)
my_vector is a variable. It’s a symbolic name that we’re using to refer to some data we’re interested in.
c(1, 2, 3) creates a vector object containing the numbers 1, 2, and 3.
This vector is the object, and it’s the actual data structure that R is storing in memory.
# remove all objects storedrm()# Create a vector 1 to 101:10
[1] 1 2 3 4 5 6 7 8 9 10
# Sampling 10 values from the vector 1:10sample(1:10, 10)
[1] 4 5 9 3 10 8 6 2 7 1
X <-sample(1:10, 10)# Extract 2nd to 5th elements of XX[2:5]
[1] 2 9 5 6
Basic Syntax
Grammar of data science.
Variable: data storage space
Data types: numeric, character, categorical, logical, special constants, etc.
Array: A set of data with columns and rows (or A set of vectors)
Data frame: A structure in which different data types are organized in a tabular form. Each properㄹty has the same size.
List: A tabular structure similar to “Data frame”. The size of each property can be different.
Grammar study is essential to save data and process operations
a = 1
b = 2
c = a+b
When there needs a lot of data, such as student grade processing
A single variable cannot represent all the data
By using vector, matrix, data frame, list, etc., it is possible to store a lot of data with one variable name.
There are many things around us are organized in a tabular form for easy data management. (e.g. attendance checking, grade, and member management, etc.)
Storing values in variables
Value assignment using =, <-, ->
# Assign 1 to Xx =1# Assign 2 to Y.y =2z = x + yz
[1] 3
x + y -> zz
[1] 3
Example of exchanging two values
Make temporary storage space and save one value in advance
x =1y =2temp = xx = yy = tempx
[1] 2
y
[1] 1
Basic data types of R
Numeric: int / num / cplx
Character: chr
Categorical: factor
Logical: True(T), FALSE(F)
Special constant
NULL: undefined value
NA: missing value
Inf & -Inf: Positive & Negative infinity
NaN: Not a Number, values cannot be computed such as 0/0, Inf/Inf, etc
In R, a vector is one of the most basic data structures used to store a sequence of elements of the same type. Vectors can hold numeric, character, or logical data. They are a fundamental part of R programming, especially for statistical operations.
Creating a Vector
You can create a vector in R using the c() function, which combines individual values into a single vector
R supports vectorized operations, meaning you can perform operations on entire vectors without needing to loop through individual elements:
# Adding a constant to each element of a numeric vectornumeric_vector +1# Output: 2 3 4 5 6
[1] 2 3 4 5 6
# Element-wise addition of two vectorsother_vector <-c(5, 4, 3, 2, 1)numeric_vector + other_vector # Output: 6 6 6 6 6
[1] 6 6 6 6 6
Common Functions with Vectors
Here are some basic functions you can use with vectors:
length(): Returns the number of elements in a vector.
sum(): Sums all elements (for numeric vectors).
mean(): Calculates the average (for numeric vectors).
Example:
length(numeric_vector) # Output: 5
[1] 5
sum(numeric_vector) # Output: 15
[1] 15
mean(numeric_vector) # Output: 3
[1] 3
More Practices..
# Create a vector with 7 elements by increasing the numbers 1 to 7 by 1.1:7
[1] 1 2 3 4 5 6 7
# Decrease by 1 from 7 to 1 to create a vector with 7 elements.7:1
[1] 7 6 5 4 3 2 1
vector(length =5)
[1] FALSE FALSE FALSE FALSE FALSE
# Create a vector consisting of 1 to 5 elements. Same as 1:5c(1:5)
[1] 1 2 3 4 5
# Create a vector of elements 1 to 6 by combining elements 1 to 3 and elements 4 to 6c(1, 2, 3, c(4:6))
[1] 1 2 3 4 5 6
# Store a vector consisting of 1 to 3 elements in xx =c(1, 2, 3) x
[1] 1 2 3
# Create y as an empty vectory =c() # Created by adding the c(1:3) vector to the existing y vectory =c(y, c(1:3)) y
[1] 1 2 3
# Create a vector from 1 to 10 in increments of 2seq(from =1, to =10, by =2)
[1] 1 3 5 7 9
# Same code with aboveseq(1, 10, by =2)
[1] 1 3 5 7 9
# Create a vector with 11 elements from 0 to 1 in increments of 0.1seq(0, 1, by =0.1)
[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
# Create a vector with 11 elements from 0 to 1seq(0, 1, length.out =11)
[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
# Create a vector by repeating the (1, 2, 3) vector twicerep(c(1:3), times =2)
[1] 1 2 3 1 2 3
# (1, 2, 3) Creates a vector by repeating the individual elements of the vector twicerep(c(1:3), each =2)
[1] 1 1 2 2 3 3
x =c(2, 4, 6, 8, 10)# Find the length (size) of the x vectorlength(x)
[1] 5
# Find the value of element 1 of the x vectorx[1]
[1] 2
# An error occurs if you enter elements 1, 2, and 3 of the x vector.# x[1, 2, 3] # When finding elements 1, 2, and 3 of the x vector, they must be grouped into a vector.x[c(1, 2, 3)]
[1] 2 4 6
# Output the value excluding elements 1, 2, and 3 from the x vectorx[-c(1, 2, 3)]
[1] 8 10
# Print elements 1 to 3 in the x vectorx[c(1:3)]
[1] 2 4 6
# Add 2 to each individual element of the x vectorx =c(1, 2, 3, 4)y =c(5, 6, 7, 8)z =c(3, 4)w =c(5, 6, 7)x+2
[1] 3 4 5 6
# Since the size of the x vector and y vector are the same, each element is addedx + y
[1] 6 8 10 12
# If the x vector is an integer multiple of the size of the z vector, add the smaller vector elements in a circular motion.x + z
[1] 4 6 6 8
# Operation error because the sizes of x and w are not integer multiplesx + w
Warning in x + w: longer object length is not a multiple of shorter object
length
[1] 6 8 10 9
# Check if element value of x vector is greater than 5x >5
[1] FALSE FALSE FALSE FALSE
# Check if all elements of the x vector are greater than 5all(x >5)
[1] FALSE
# Check if any of the element values of the x vector are greater than 5any(x >5)
[1] FALSE
x =1:10# Extract the first 6 elements of datahead(x)
[1] 1 2 3 4 5 6
# Extract the last 6 elements of datatail(x)
[1] 5 6 7 8 9 10
# Extract the first 3 elements of datahead(x, 3)
[1] 1 2 3
# Extract the last 3 elements of datatail(x, 3)
[1] 8 9 10
Sets
x =c(1, 2, 3)y =c(3, 4, 5)z =c(3, 1, 2)# Union setunion(x, y)
[1] 1 2 3 4 5
# Intersection setintersect(x, y)
[1] 3
# Set difference (X - Y)setdiff(x, y)
[1] 1 2
# Set difference (Y - X)setdiff(y, x)
[1] 4 5
# Compare whether x and y have the same elementssetequal(x, y)
[1] FALSE
# Compare whether x and z have the same elementssetequal(x, z)
[1] TRUE
Vectorized codes
c(1, 2, 4) +c(2, 3, 5)
[1] 3 5 9
X <-c(1,2,4,5)X *2
[1] 2 4 8 10
Recycling rule
1:4+c(1, 2)
[1] 2 4 4 6
X<-c(1,2,4,5)X *2
[1] 2 4 8 10
1:4+1:3
Warning in 1:4 + 1:3: longer object length is not a multiple of shorter object
length
[1] 2 4 6 5
Array
Understanding Arrays in R: Concepts and Examples
Arrays are a fundamental data structure in R that extend vectors by allowing you to store multi-dimensional data. While a vector has one dimension, arrays in R can have two or more dimensions, making them incredibly versatile for complex data organization.
What is an Array in R?
An array in R is a collection of elements of the same type arranged in a grid of a specified dimensionality. It is a multi-dimensional data structure that can hold values in more than two dimensions. Arrays are particularly useful in scenarios where operations on multi-dimensional data are required, such as matrix computations, tabulations, and various applications in data analysis and statistics.
Creating an Array
To create an array in R, you can use the array function. This function takes a vector of data and a vector of dimensions as arguments. For example:
# Create a 2x3 arraymy_array <-array(1:6, dim =c(2, 3))print(my_array)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
This code snippet creates a 2x3 array (2 rows and 3 columns) with the numbers 1 to 6.
Accessing Array Elements
Elements within an array can be accessed using indices for each dimension in square brackets []. For example:
# Access the element in the 1st row and 2nd columnelement <- my_array[1, 2]print(element)
[1] 3
Modifying Arrays
Just like vectors, you can modify the elements of an array by accessing them using their indices and assigning new values. For example:
# Modify the element in the 1st row and 2nd column to be 20my_array[1, 2] <-20print(my_array)
[,1] [,2] [,3]
[1,] 1 20 5
[2,] 2 4 6
Operations on Arrays
R allows you to perform operations on arrays. These operations can be element-wise or can involve the entire array. For example, you can add two arrays of the same dimensions, and R will perform element-wise addition.
Example: Creating and Manipulating a 3D Array
# Create a 3x2x2 arraymy_3d_array <-array(1:12, dim =c(3, 2, 2))print(my_3d_array)
# Various matrix operations using the operators in [Table 3-7]# Store two 2×2 matrices in x and y, respectivelyx =array(1:4, dim =c(2, 2))y =array(5:8, dim =c(2, 2))x
# If the center value is 1, apply the function row by rowapply(x, 1, mean)
[1] 5.5 6.5 7.5
# If the center value is 2, apply the function to each columnapply(x, 2, mean)
[1] 2 5 8 11
x =array(1:12, c(3, 4))dim(x)
[1] 3 4
x =array(1:12, c(3, 4))# Randomly mix and extract array elementssample(x)
[1] 8 4 11 10 12 9 1 7 3 2 5 6
# Select and extract 10 elements from the arraysample(x, 10)
[1] 3 7 5 1 10 4 12 11 6 8
library(dplyr)# ?sample# The extraction probability for each element can be variedsample(x, 10, prob =c(1:12)/24)
[1] 12 11 5 7 10 8 3 2 6 9
# You can create a sample using just numberssample(10)
[1] 5 10 9 1 3 2 7 6 8 4
Data.frame
In R, a data.frame is a two-dimensional table-like data structure that holds data in rows and columns. It’s one of the most commonly used data structures, especially when dealing with tabular data, similar to spreadsheets or SQL tables.
Characteristics of data.frame
Each column can hold different types of data (numeric, character, logical, etc.).
Each row represents a single observation, and each column represents a variable.
Columns can have different data types, but all values within a column must be of the same type.
Creating a data.frame
You can create a data.frame using the data.frame() function by combining vectors of equal length.
# Create a data frame with numeric, character, and logical columnsmy_data <-data.frame(ID =c(1, 2, 3),Name =c("John", "Sarah", "Mike"),Age =c(25, 30, 22),IsStudent =c(TRUE, FALSE, TRUE))# View the data framemy_data
ID Name Age IsStudent
1 1 John 25 TRUE
2 2 Sarah 30 FALSE
3 3 Mike 22 TRUE
Accessing Elements in a data.frame
You can access elements by referring to rows and columns:
By column name: You can use the $ operator or square brackets [ , ] to extract a column.
# Extract the 'Name' column using $my_data$Name # Output: "John" "Sarah" "Mike"
[1] "John" "Sarah" "Mike"
# Extract the 'Age' column using square bracketsmy_data[, "Age"] # Output: 25 30 22
[1] 25 30 22
By row number: You can also use row indices to access specific rows or a combination of rows and columns.
# Extract the first rowmy_data[1, ] # Output: 1 "John" 25 TRUE
ID Name Age IsStudent
1 1 John 25 TRUE
# Extract the value in the second row, third columnmy_data[2, 3] # Output: 30
[1] 30
Adding New Columns or Rows
You can add new columns or rows to an existing data.frame:
Adding a new column:
my_data$Grade <-c("A", "B", "A")my_data
ID Name Age IsStudent Grade
1 1 John 25 TRUE A
2 2 Sarah 30 FALSE B
3 3 Mike 22 TRUE A
Adding a new row:
new_row <-data.frame(ID =4, Name ="Emma", Age =28, IsStudent =FALSE, Grade ="B")my_data <-rbind(my_data, new_row)my_data
ID Name Age IsStudent Grade
1 1 John 25 TRUE A
2 2 Sarah 30 FALSE B
3 3 Mike 22 TRUE A
4 4 Emma 28 FALSE B
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Can also be written in one line like this:patients1 =data.frame(name =c("Cheolsu", "Chunhyang", "Gildong"), age =c(22, 20, 25), gender =factor(c("M", "F", "M ")), blood.type =factor(c("A", "O", "B")))patients1
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
patients$name # Print name attribute value
[1] "Cheolsu" "Chunhyang" "Gildong"
patients[1, ] # Print row 1 value
name age gender blood.type
1 Cheolsu 22 M A
patients[, 2] # Print 2nd column values
[1] 22 20 25
patients[3, 1] # Prints 3 rows and 1 column values
[1] "Gildong"
patients[patients$name=="Withdrawal", ] # Extract information about withdrawal among patients
[1] name age gender blood.type
<0 rows> (or 0-length row.names)
patients[patients$name=="Cheolsu", c("name", "age")] # Extract only Cheolsu's name and age information
name age
1 Cheolsu 22
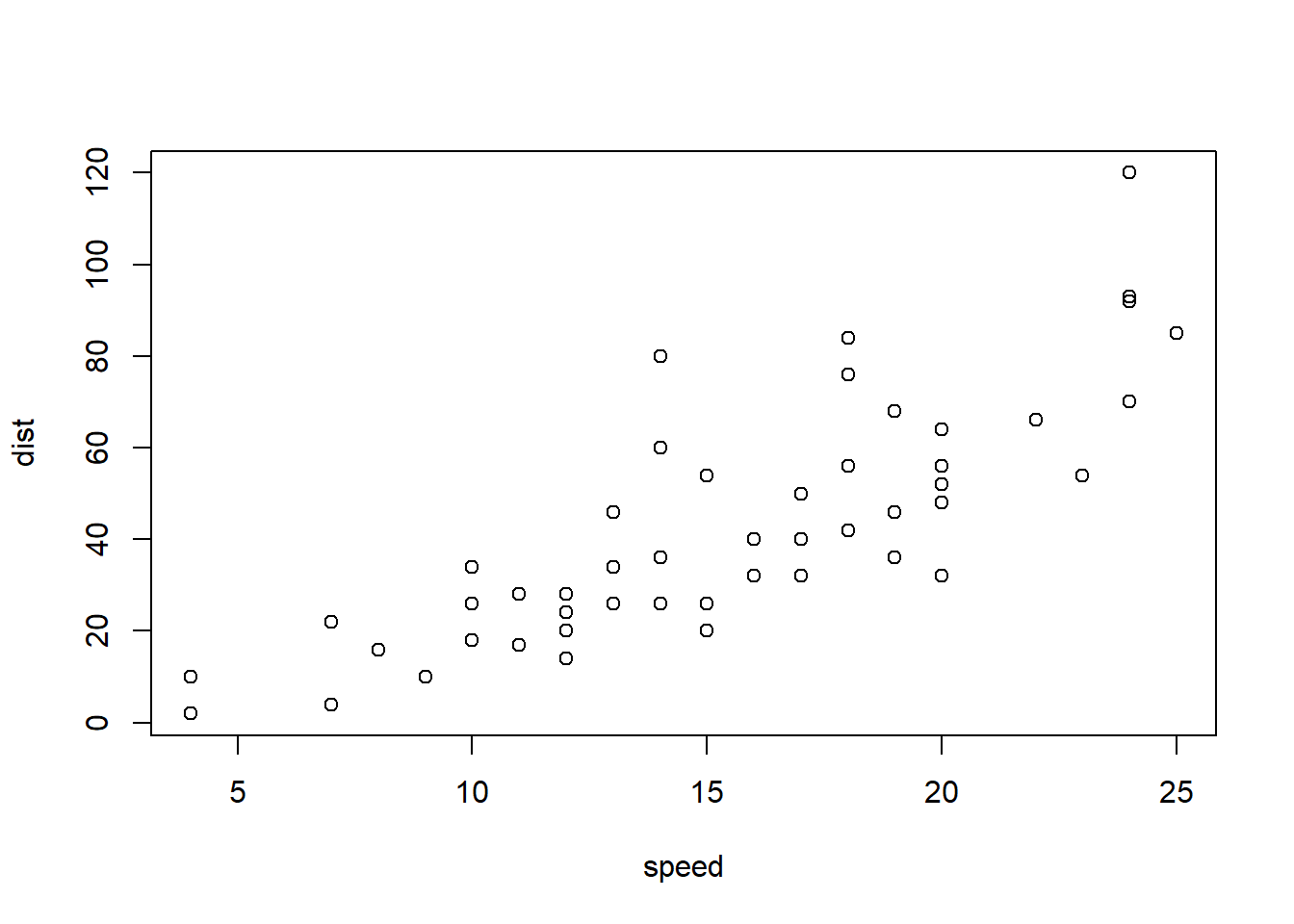
head(cars) # Check the cars data set. The basic function of the head function is to extract the first 6 data.
detach(cars) # Deactivates the use of each property of cars as a variable through the detach function# speed # Try to access the variable called speed, but there is no such variable.# Apply functions using data propertiesmean(cars$speed)
[1] 15.4
max(cars$speed)
[1] 25
# Apply a function using the with functionwith(cars, mean(speed))
[1] 15.4
with(cars, max(speed))
[1] 25
# Extract only data with speed greater than 20subset(cars, speed >20)
# merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...)name =c("Cheolsu", "Chunhyang", "Gildong")age =c(22, 20, 25)gender =factor(c("M", "F", "M"))blood.type =factor(c("A", "O", "B"))patients1 =data.frame(name, age, gender)patients1
name age gender
1 Cheolsu 22 M
2 Chunhyang 20 F
3 Gildong 25 M
patients2 =data.frame(name, blood.type)patients2
name blood.type
1 Cheolsu A
2 Chunhyang O
3 Gildong B
patients =merge(patients1, patients2, by ="name")patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# If there are no column variables with the same name, when merging them into by.x and by.y of the merge function# You must enter the attribute name of each column to be used.name1 =c("Cheolsu", "Chunhyang", "Gildong")name2 =c("Minsu", "Chunhyang", "Gildong")age =c(22, 20, 25)gender =factor(c("M", "F", "M"))blood.type =factor(c("A", "O", "B"))patients1 =data.frame(name1, age, gender)patients1
name1 age gender
1 Cheolsu 22 M
2 Chunhyang 20 F
3 Gildong 25 M
patients2 =data.frame(name2, blood.type)patients2
name2 blood.type
1 Minsu A
2 Chunhyang O
3 Gildong B
name1 age gender blood.type
1 Chunhyang 20 F O
2 Gildong 25 M B
patients =merge(patients1, patients2, by.x ="name1", by.y ="name2", all =TRUE)patients
name1 age gender blood.type
1 Cheolsu 22 M <NA>
2 Chunhyang 20 F O
3 Gildong 25 M B
4 Minsu NA <NA> A
x =array(1:12, c(3, 4))# Currently x is not a data frameis.data.frame(x)
[1] FALSE
as.data.frame(x)
V1 V2 V3 V4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
# Just calling the is.data.frame function does not turn x into a data frameis.data.frame(x)
[1] FALSE
# Convert x to data frame format with the as.data.frame functionx =as.data.frame(x)x
V1 V2 V3 V4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
# Verify that x has been converted to data frame formatis.data.frame(x)
[1] TRUE
# When converting to a data frame, automatically assigned column names are reassigned to the names function.names(x) =c("1st", "2nd", "3rd", "4th")x
1st 2nd 3rd 4th
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
List
In R, a list is a data structure that can store multiple types of elements, including vectors, other lists, data frames, functions, and more. Unlike vectors or data frames, lists can contain elements of different types and lengths.
Characteristics of a List
A list can hold different data types (numeric, character, logical, etc.) within the same structure.
Each element in a list can be of different lengths and types, including even other lists or data frames.
Creating a List
You can create a list in R using the list() function:
# Creating a list with different data typesmy_list <-list(Name ="John",Age =25,Scores =c(90, 85, 88),Passed =TRUE)# View the listmy_list
lapply(): Applies a function to each element of a list and returns a list.
# Apply the 'mean' function to each element (for lists with numeric values)num_list <-list(a =c(1, 2, 3), b =c(4, 5, 6))lapply(num_list, mean)
$a
[1] 2
$b
[1] 5
unlist(): Converts a list into a vector (flattening it).
# Convert a list to a vectorunlist(my_list)
Name Age Scores1 Scores2 Scores3 Passed
"John" "26" "90" "85" "88" "TRUE"
More Practices
# List #patients =data.frame(name =c("Cheolsu", "Chunhyang", "Gildong"), age =c(22, 20, 25), gender =factor(c("M", "F", "M ")), blood.type =factor(c("A", "O", "B")))no.patients =data.frame(day =c(1:6), no =c(50, 60, 55, 52, 65, 58))# Simple addition of datalistPatients =list(patients, no.patients)listPatients
[[1]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
[[2]]
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Add names to each datalistPatients =list(patients=patients, no.patients = no.patients)listPatients
$patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
$no.patients
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Enter element namelistPatients$patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter indexlistPatients[[1]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter the element name in ""listPatients[["patients"]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter the element name in ""listPatients[["no.patients"]]
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Calculate the average of no.patients elementslapply(listPatients$no.patients, mean)
$day
[1] 3.5
$no
[1] 56.66667
# Calculate the average of the patients elements. Anything that is not in numeric form is not averaged.lapply(listPatients$patients, mean)
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
$name
[1] NA
$age
[1] 22.33333
$gender
[1] NA
$blood.type
[1] NA
sapply(listPatients$no.patients, mean)
day no
3.50000 56.66667
# If the simplify option of sapply() is set to F, the same result as lapply() is returned.sapply(listPatients$no.patients, mean, simplify = F)