name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Can also be written in one line like this:patients1 =data.frame(name =c("Cheolsu", "Chunhyang", "Gildong"), age =c(22, 20, 25), gender =factor(c("M", "F", "M ")), blood.type =factor(c("A", "O", "B")))patients1
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
patients$name # Print name attribute value
[1] "Cheolsu" "Chunhyang" "Gildong"
patients[1, ] # Print row 1 value
name age gender blood.type
1 Cheolsu 22 M A
patients[, 2] # Print 2nd column values
[1] 22 20 25
patients[3, 1] # Prints 3 rows and 1 column values
[1] "Gildong"
patients[patients$name=="Withdrawal", ] # Extract information about withdrawal among patients
[1] name age gender blood.type
<0 rows> (or 0-length row.names)
patients[patients$name=="Cheolsu", c("name", "age")] # Extract only Cheolsu's name and age information
name age
1 Cheolsu 22
head(cars) # Check the cars data set. The basic function of the head function is to extract the first 6 data.
detach(cars) # Deactivates the use of each property of cars as a variable through the detach function# speed # Try to access the variable called speed, but there is no such variable.# Apply functions using data propertiesmean(cars$speed)
[1] 15.4
max(cars$speed)
[1] 25
# Apply a function using the with functionwith(cars, mean(speed))
[1] 15.4
with(cars, max(speed))
[1] 25
# Extract only data with speed greater than 20subset(cars, speed >20)
# merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...)name =c("Cheolsu", "Chunhyang", "Gildong")age =c(22, 20, 25)gender =factor(c("M", "F", "M"))blood.type =factor(c("A", "O", "B"))patients1 =data.frame(name, age, gender)patients1
name age gender
1 Cheolsu 22 M
2 Chunhyang 20 F
3 Gildong 25 M
patients2 =data.frame(name, blood.type)patients2
name blood.type
1 Cheolsu A
2 Chunhyang O
3 Gildong B
patients =merge(patients1, patients2, by ="name")patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# If there are no column variables with the same name, when merging them into by.x and by.y of the merge function# You must enter the attribute name of each column to be used.name1 =c("Cheolsu", "Chunhyang", "Gildong")name2 =c("Minsu", "Chunhyang", "Gildong")age =c(22, 20, 25)gender =factor(c("M", "F", "M"))blood.type =factor(c("A", "O", "B"))patients1 =data.frame(name1, age, gender)patients1
name1 age gender
1 Cheolsu 22 M
2 Chunhyang 20 F
3 Gildong 25 M
patients2 =data.frame(name2, blood.type)patients2
name2 blood.type
1 Minsu A
2 Chunhyang O
3 Gildong B
name1 age gender blood.type
1 Chunhyang 20 F O
2 Gildong 25 M B
patients =merge(patients1, patients2, by.x ="name1", by.y ="name2", all =TRUE)patients
name1 age gender blood.type
1 Cheolsu 22 M <NA>
2 Chunhyang 20 F O
3 Gildong 25 M B
4 Minsu NA <NA> A
x =array(1:12, c(3, 4))# Currently x is not a data frameis.data.frame(x)
[1] FALSE
as.data.frame(x)
V1 V2 V3 V4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
# Just calling the is.data.frame function does not turn x into a data frameis.data.frame(x)
[1] FALSE
# Convert x to data frame format with the as.data.frame functionx =as.data.frame(x)x
V1 V2 V3 V4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
# Verify that x has been converted to data frame formatis.data.frame(x)
[1] TRUE
# When converting to a data frame, automatically assigned column names are reassigned to the names function.names(x) =c("1st", "2nd", "3rd", "4th")x
1st 2nd 3rd 4th
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
List
# List #patients =data.frame(name =c("Cheolsu", "Chunhyang", "Gildong"), age =c(22, 20, 25), gender =factor(c("M", "F", "M ")), blood.type =factor(c("A", "O", "B")))no.patients =data.frame(day =c(1:6), no =c(50, 60, 55, 52, 65, 58))# Simple addition of datalistPatients =list(patients, no.patients)listPatients
[[1]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
[[2]]
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Add names to each datalistPatients =list(patients=patients, no.patients = no.patients)listPatients
$patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
$no.patients
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Enter element namelistPatients$patients
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter indexlistPatients[[1]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter the element name in ""listPatients[["patients"]]
name age gender blood.type
1 Cheolsu 22 M A
2 Chunhyang 20 F O
3 Gildong 25 M B
# Enter the element name in ""listPatients[["no.patients"]]
day no
1 1 50
2 2 60
3 3 55
4 4 52
5 5 65
6 6 58
# Calculate the average of no.patients elementslapply(listPatients$no.patients, mean)
$day
[1] 3.5
$no
[1] 56.66667
# Calculate the average of the patients elements. Anything that is not in numeric form is not averaged.lapply(listPatients$patients, mean)
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
returning NA
$name
[1] NA
$age
[1] 22.33333
$gender
[1] NA
$blood.type
[1] NA
sapply(listPatients$no.patients, mean)
day no
3.50000 56.66667
# If the simplify option of sapply() is set to F, the same result as lapply() is returned.sapply(listPatients$no.patients, mean, simplify = F)
$day
[1] 3.5
$no
[1] 56.66667
Class
Pop-up Qz
# Let a vectorV1 =c(1,2,3,4,5,NA,9,10)
How can we get a vector of integers less than 4 from V1?
1) V1[V1 < 4 & !is.na(V1)]
2) V1[V1 < 4 | !is.na(V1)]
3) V1(V1 < 4 | !is.na(V1))
4) V1[V1 < 4] & V1[!is.na(V1)]
# Let a data frame as belowdf <-data.frame(name =c("John", "Mary", "Mark"),age =c(30,16,21),gender =c("M", "F", "M"))df
name age gender
1 John 30 M
2 Mary 16 F
3 Mark 21 M
Make an R code to filter if gender is ‘male’ and age is 19 or above.
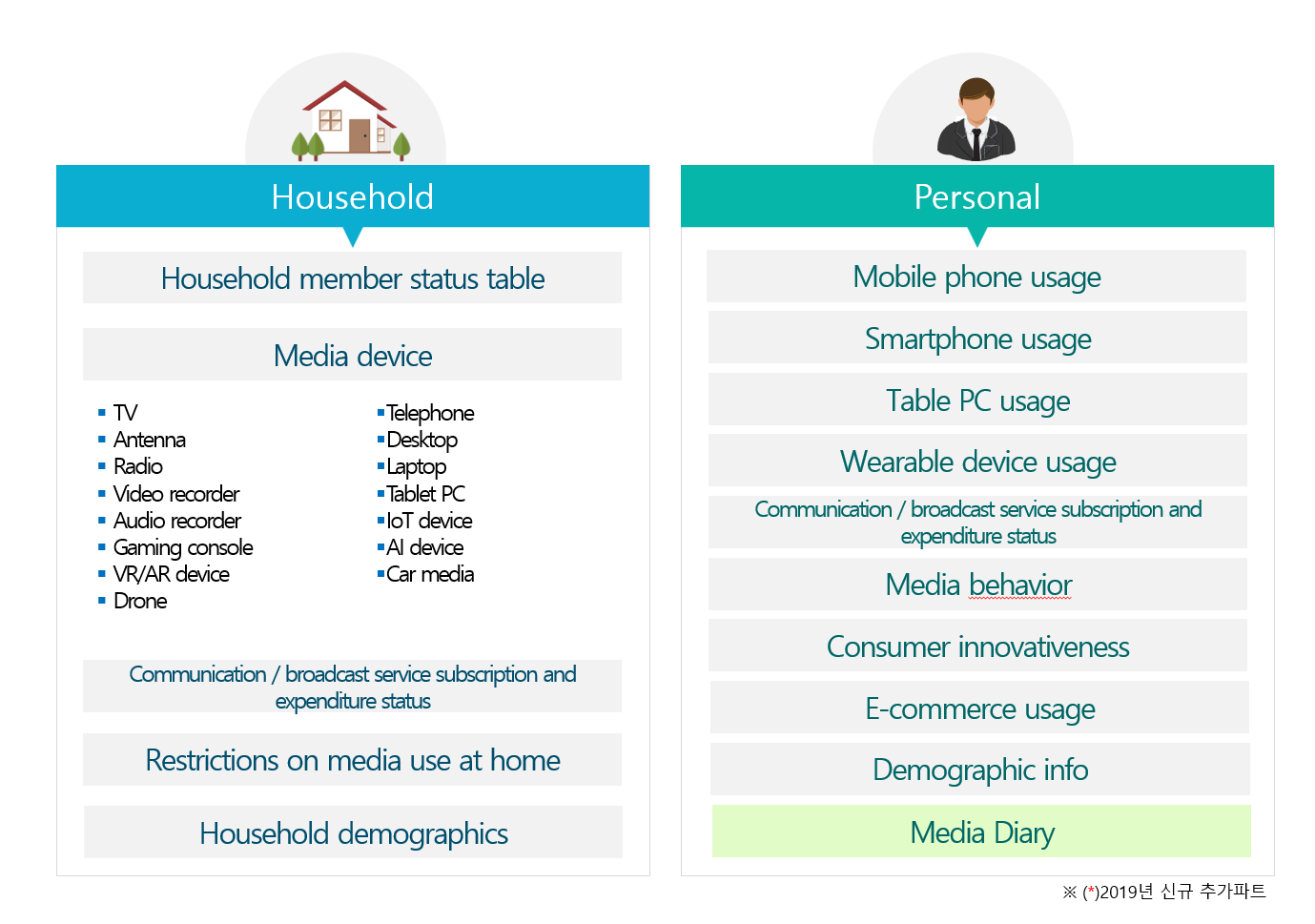
Since 2010 KISDI has surveyed the same people annually about people’s media behavior (Smartphone brand, telecom company, spending related to media, SNS usage, and so on)
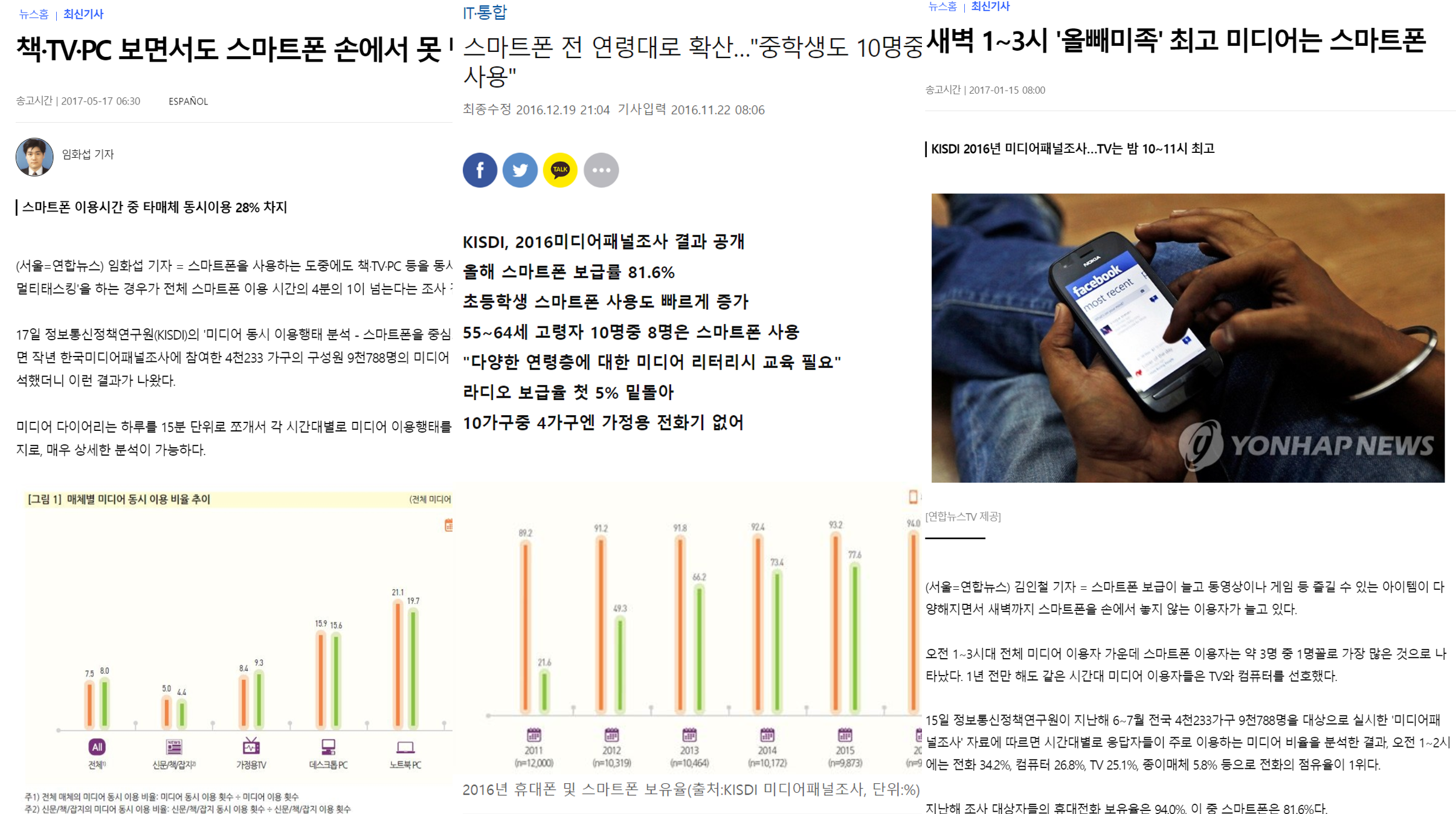
Korea Media Panel data is used in news articles based on media statistics, such as the article below.
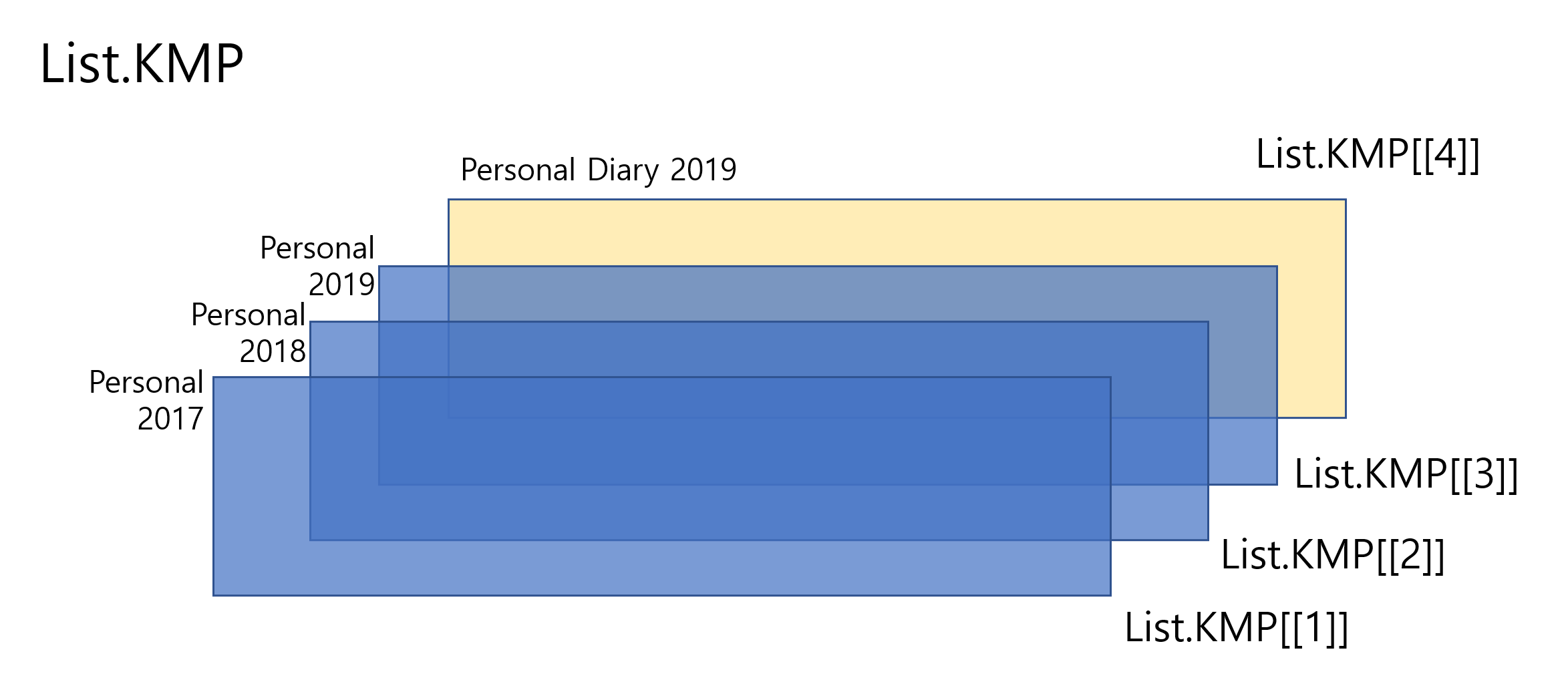
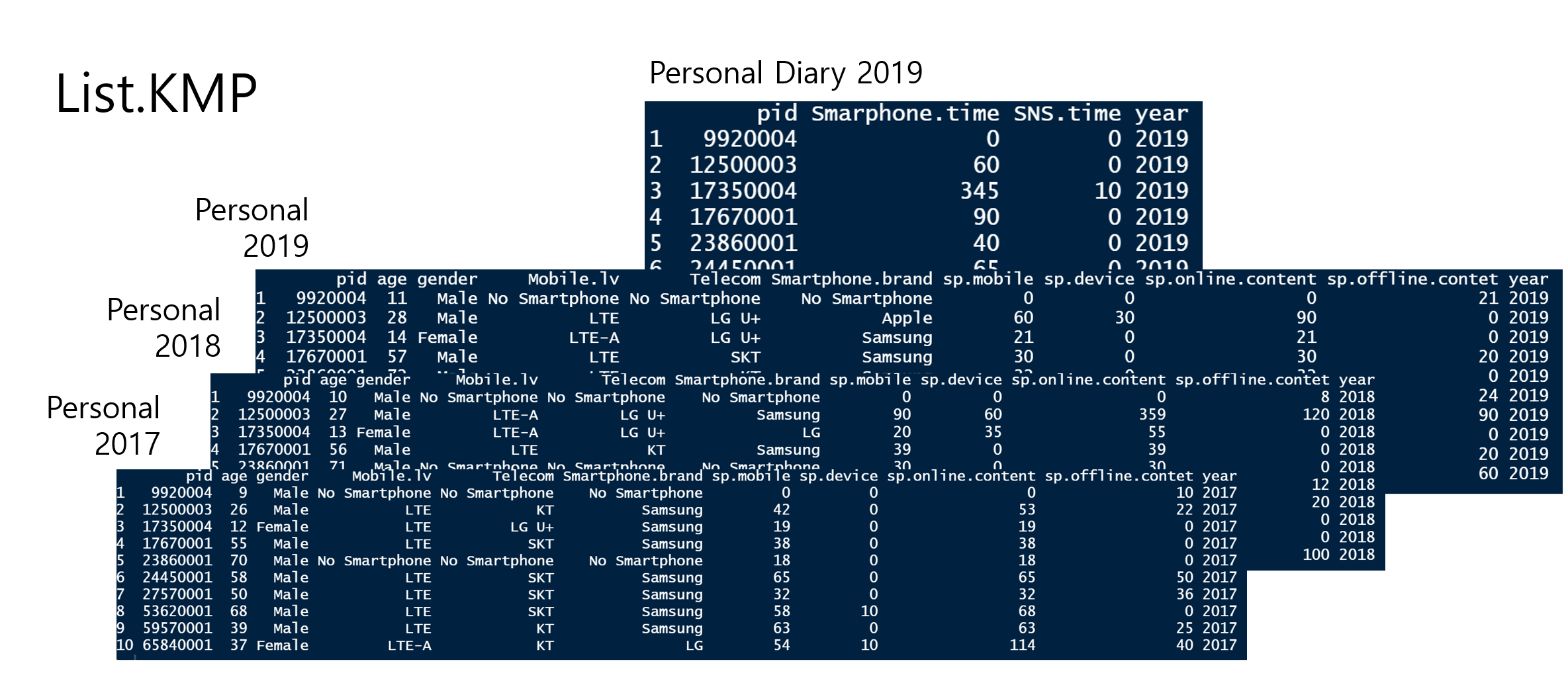
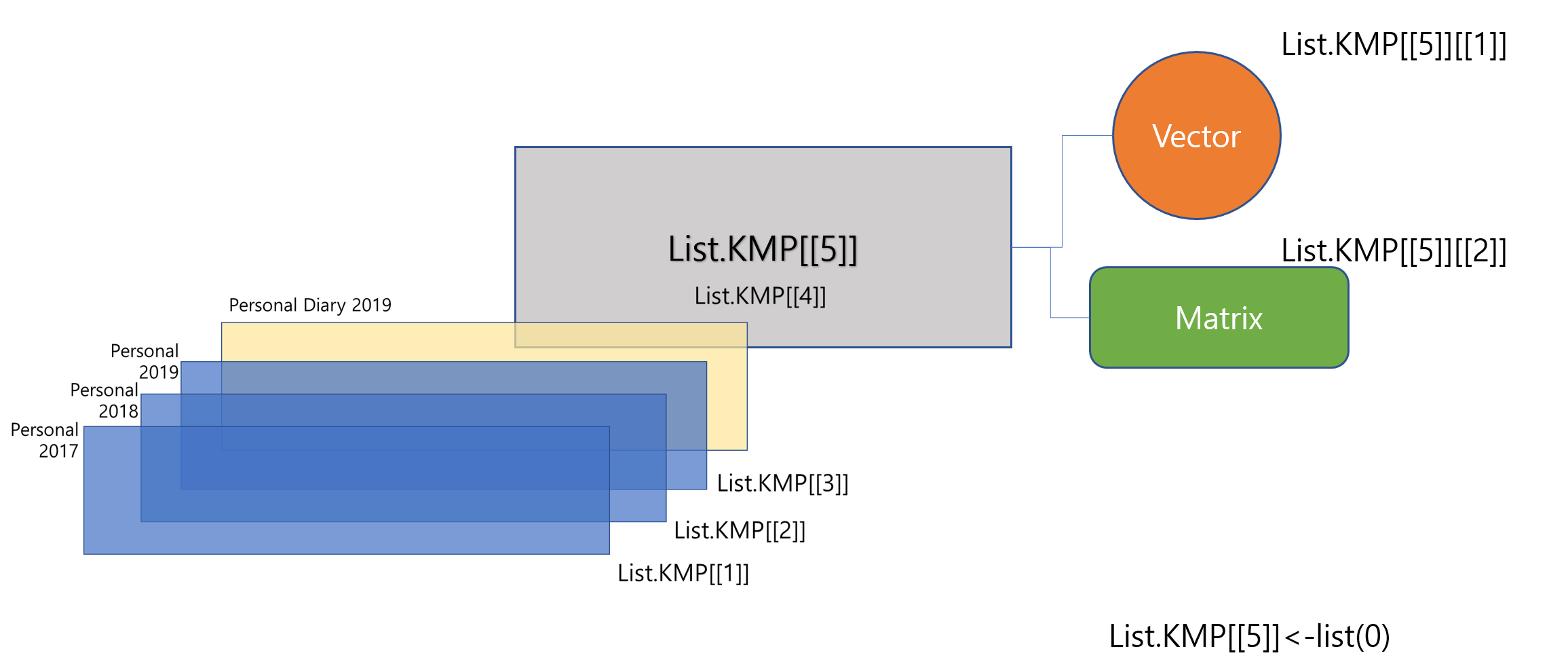
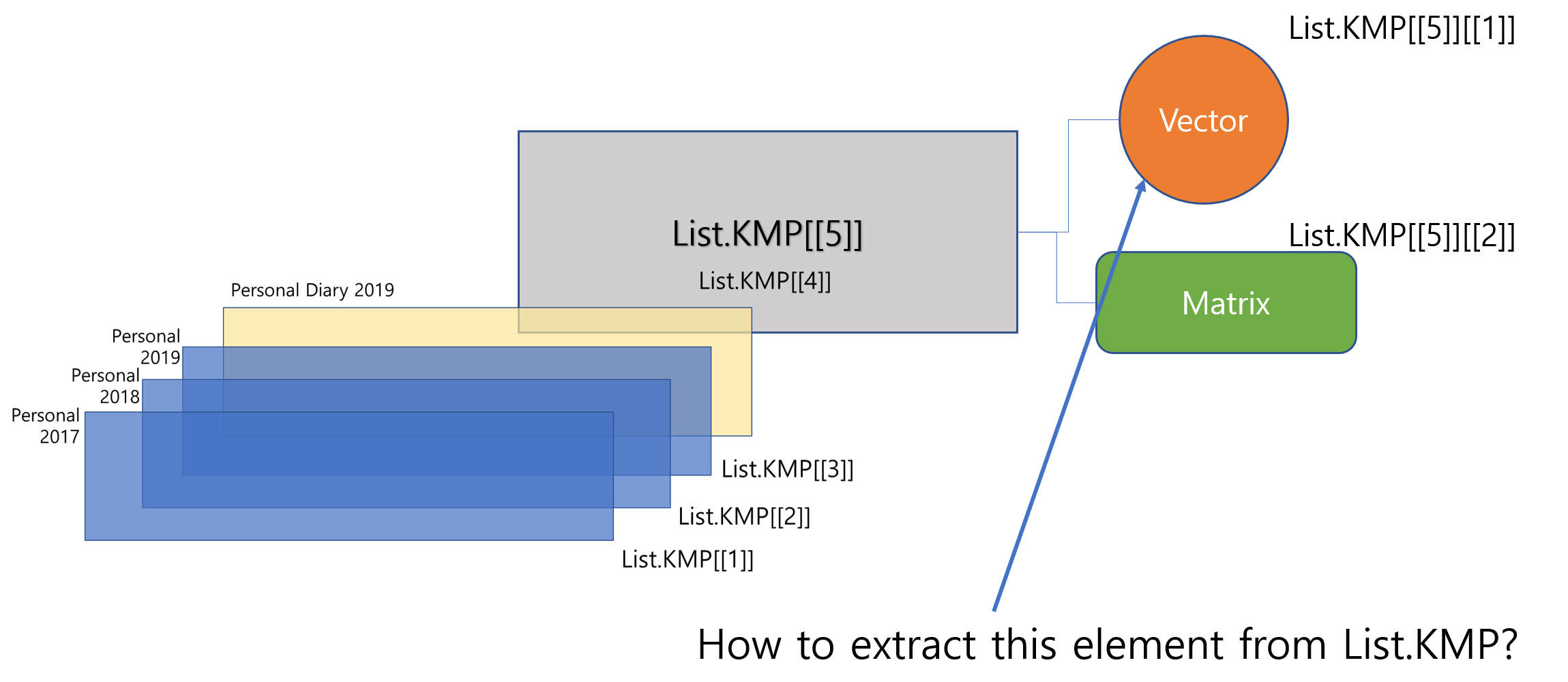
# The first element of the fifth elementList.KMP[[5]][[1]]<-c(1:10)# The second element of the fifth elementList.KMP[[5]][[2]]<-matrix(c(1:12), nrow=4)
pid age gender Mobile.lv Telecom Smartphone.brand sp.mobile
1 9920004 9 Male No Smartphone No Smartphone No Smartphone 0
2 12500003 26 Male LTE KT Samsung 42
3 17350004 12 Female LTE LG U+ Samsung 19
4 17670001 55 Male LTE SKT Samsung 38
5 23860001 70 Male No Smartphone No Smartphone No Smartphone 18
6 24450001 58 Male LTE SKT Samsung 65
7 27570001 50 Male LTE SKT Samsung 32
8 53620001 68 Male LTE SKT Samsung 58
9 59570001 39 Male LTE KT Samsung 63
10 65840001 37 Female LTE-A KT LG 54
sp.device sp.online.content sp.offline.contet year
1 0 0 10 2017
2 0 53 22 2017
3 0 19 0 2017
4 0 38 0 2017
5 0 18 0 2017
6 0 65 50 2017
7 0 32 36 2017
8 10 68 0 2017
9 0 63 25 2017
10 10 114 40 2017
# Summary Statisticssummary(p17_df)
pid age gender Mobile.lv
Min. : 9920004 Min. : 9.00 Male :8 3G :0
1st Qu.:17430003 1st Qu.:28.75 Female:2 LTE :7
Median :24155001 Median :44.50 LTE-A :1
Mean :31235002 Mean :42.40 5G :0
3rd Qu.:47107501 3rd Qu.:57.25 No Smartphone:2
Max. :65840001 Max. :70.00
Telecom Smartphone.brand sp.mobile sp.device
SKT :4 Samsung :7 Min. : 0.00 Min. : 0
KT :3 No Smartphone:2 1st Qu.:22.25 1st Qu.: 0
LG U+ :1 LG :1 Median :40.00 Median : 0
MVNO :0 Apple :0 Mean :38.90 Mean : 2
No Smartphone:2 Pantech :0 3rd Qu.:57.00 3rd Qu.: 0
Xiaomi :0 Max. :65.00 Max. :10
(Other) :0
sp.online.content sp.offline.contet year
Min. : 0.00 Min. : 0.00 Min. :2017
1st Qu.: 22.25 1st Qu.: 0.00 1st Qu.:2017
Median : 45.50 Median :16.00 Median :2017
Mean : 47.00 Mean :18.30 Mean :2017
3rd Qu.: 64.50 3rd Qu.:33.25 3rd Qu.:2017
Max. :114.00 Max. :50.00 Max. :2017
Among 10 people, How many people did use Samsung phone at 2017?
How much did people spend for the mobile communication on average?
Do the same thing to 2019 data set and answer the questions below.
In 2019, how many people did use Samsung phone?
Draw boxplot of people’s spending on the mobile communication
*Hint: use boxplot()